Set up Apache Hue to use different Hadoop components.
-
In the Hue UI, create an admin user with the password that you used while Creating a Cluster.
-
Navigate to Administer users and do the following:
- Select the Hue user.
- Update the password.
- Make the user allowed to sign in as a Hue user for subsequent logins.
You can create more users according to your requirement.
Note
For secure clusters, ensure that you select the Create home directory checkbox and create the user in utility node using the sudo useradd <new_user> command to manage the access policies using ranger.
-
To run the DistCp and MapReduce applications, add the MapReduce library to YARN classpath. To add the library, follow these steps:
- On the Ambari UI, under YARN, select Configs.
- Search for
yarn.application.classpath.
- Copy the following configuration and paste it for the
yarn.application.classpath value:$HADOOP_CONF_DIR,/usr/lib/hadoop-mapreduce/*,/usr/lib/hadoop/*,/usr/lib/hadoop/lib/*,/usr/lib/hadoop-hdfs/*,/usr/lib/hadoop-hdfs/lib/*,/usr/lib/hadoop-yarn/*,/usr/lib/hadoop-yarn/lib/*
- Save and restart the YARN, Oozie, and MapReduce services.
-
Configure Sqoop. To configure, follow these steps:
- Copy mysql-connector to oozie classpath.
sudo cp /usr/lib/oozie/embedded-oozie-server/webapp/WEB-INF/lib/mysql-connector-java.jar /usr/lib/oozie/share/lib/sqoop/
sudo su oozie -c "hdfs dfs -put /usr/lib/oozie/share/lib/sqoop/mysql-connector-java.jar /user/oozie/share/lib/sqoop"
- Restart the Oozie service through Ambari.
- The Sqoop jobs run from worker nodes.
In Big Data Service clusters with version 3.0.7 or later, access to the hue mysql user is available from all worker nodes.
For clusters with prior versions, run the grant statements as described in Step 2 of the secure and nonsecure cluster sections of Configuring Apache Hue. While running the commands, replace the local host with the worker host name and repeat this for each worker node in the cluster. For example:
grant all privileges on *.* to 'hue'@'wn_host_name ';
grant all on hue.* to 'hue'@'wn_host_name';
alter user 'hue'@'wn_host_name' identified by 'secretpassword';
flush privileges;
-
On the master or utility node, from the following directory, use the spark-related jars and add as dependency to your spark project. For example, copy spark-core and spark-sql jars into lib/ for sbt project.
/usr/lib/oozie/share/lib/spark/spark-sql_2.12-3.0.2.odh.1.0.ce4f70b73b6.jar
/usr/lib/oozie/share/lib/spark/spark-core_2.12-3.0.2.odh.1.0.ce4f70b73b6.jar
The following is an example of word count code. Assemble the code into JAR:
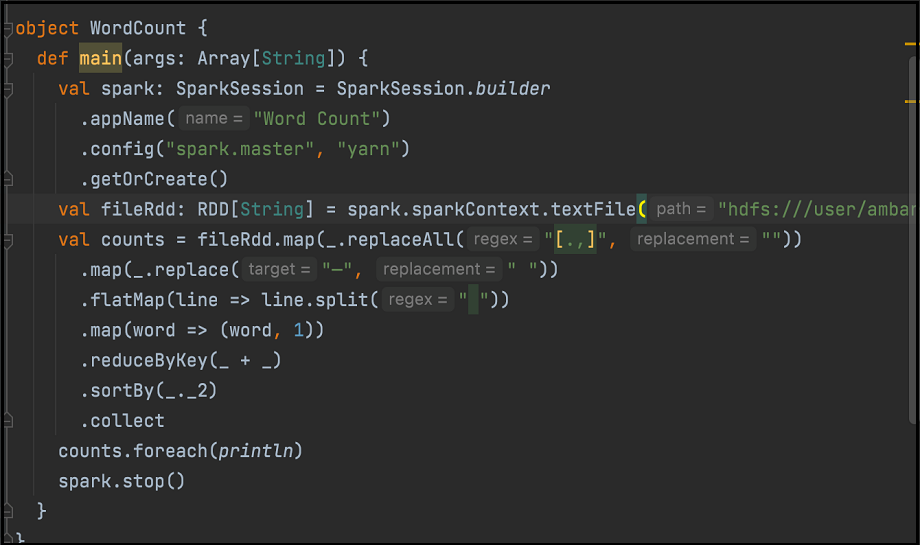
On the Hue Spark interface, use the relevant jars to run the Spark job.
-
To run MapReduce through Oozie, do the following:
- Copy
oozie-sharelib-oozie-5.2.0.jar (contains the OozieActionConfigurator class) into your sample code.
- Define the mapper and reducer classes as given in any standard word count MapReduce example.
- Create another class as shown here:
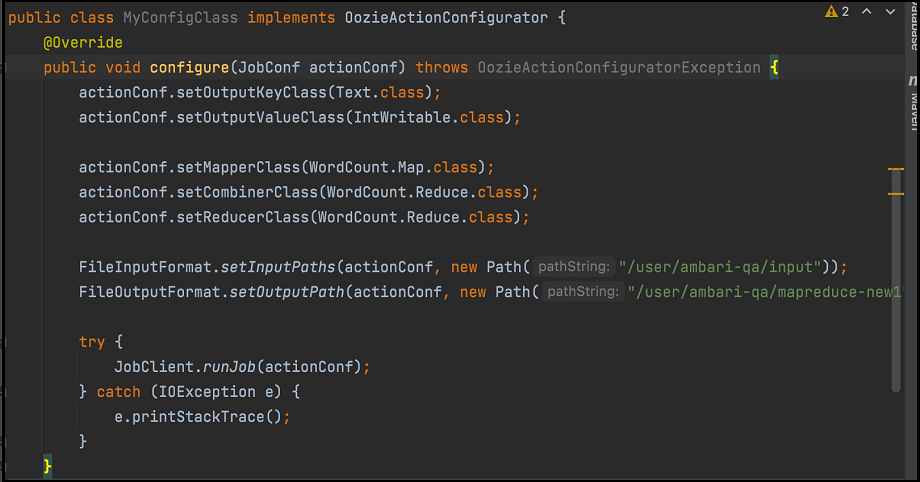
Package the code as shown in the previous image along with the mapper and reducer classes into a jar and do the following:
- Upload it to HDFS through Hue file browser.
- Provide the following to run MapReduce program, where
oozie.action.config.class points to the fully qualified class name in the snippet as shown in the previous image.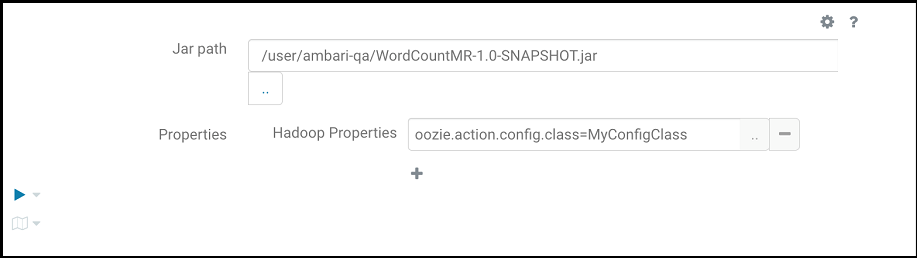
-
Configure HBase.
In Big Data Service clusters with version 3.0.7 or later, you must enable the Hue HBase Module using Apache Ambari. 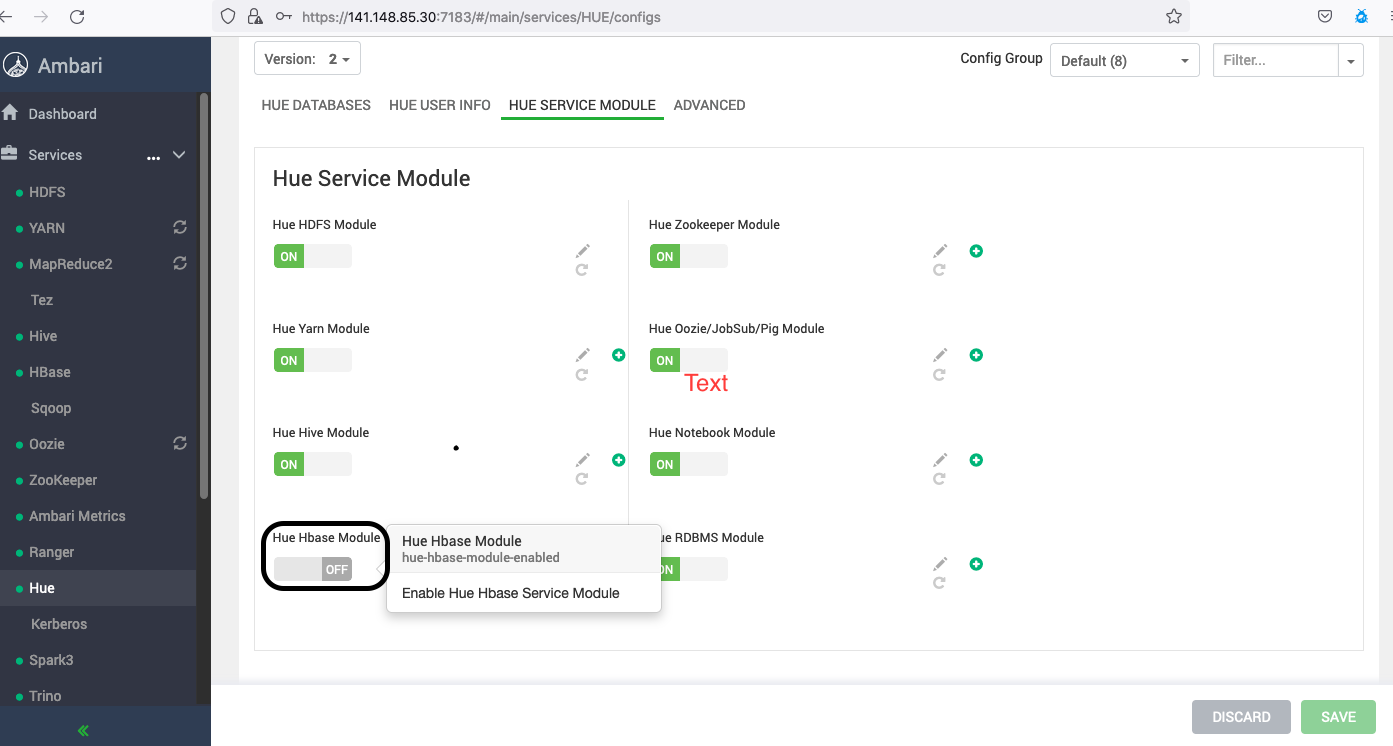
Hue interacts with the HBase Thrift server. Therefore, to access HBase, you must start the Thrift server. Follow these steps:
- After you add the HBase service on the Ambari page, navigate to Custom Hbase-Site.xml (from HBase, go to Configs, and under Advanced, select Custom Hbase-Site.xml).
- Add the following parameters by substituting the keytab or principal.
hbase.thrift.support.proxyuser=true
hbase.regionserver.thrift.http=true
##Skip the below configs if this is a non-secure cluster
hbase.thrift.security.qop=auth
hbase.thrift.keytab.file=/etc/security/keytabs/hbase.service.keytab
hbase.thrift.kerberos.principal=hbase/_HOST@BDSCLOUDSERVICE.ORACLE.COM
hbase.security.authentication.spnego.kerberos.keytab=/etc/security/keytabs/spnego.service.keytab
hbase.security.authentication.spnego.kerberos.principal=HTTP/_HOST@BDSCLOUDSERVICE.ORACLE.COM
- Run the following commands on the master nodes terminal:
# sudo su hbase
//skip kinit command if this is a non-secure cluster
# kinit -kt /etc/security/keytabs/hbase.service.keytab hbase/<master_node_host>@BDSCLOUDSERVICE.ORACLE.COM
# hbase thrift start
- Sign in to the utility node where Hue is installed.
- Open the
sudo vim /etc/hue//conf/pseudo-distributed.ini file and remove hbase from app_blacklist.
# Comma separated list of apps to not load at startup.
# e.g.: pig, zookeeper
app_blacklist=search, security, impala, hbase, pig
- Restart Hue from Ambari.
- Ranger governs access to the HBase service. Therefore, to use Hue and access HBase tables on a secure cluster, you must have access to the HBase service from Ranger.
-
Configure the script action workflow:
- Sign in to Hue.
- Create a script file and upload it to Hue.
- Sign in to Hue, and then in the leftmost navigation menu, select Scheduler.
- Workflow, and then select My Workflow to create a workflow.
- Select the shell icon to drag the script action to the Drop your action here area.
- Select the script from the Shell command dropdown.
- Select the workflow from the FILES dropdown.
- Select the save icon.
- Select the workflow from the folder structure, and then select the submit icon.
Note While executing any shell action in a Hue workflow, if the job is stuck or fails because of errors such as
Permission Denied or Exit code[1], complete the following instructions to resolve the issue.
- Ensure that all the required files (script file and other related files) are available at the specified location as mentioned in the workflow, with the required permissions to the workflow execution user (hue logged-in user).
- Sometimes, such as spark-submit, if the you submit a Spark job without a specific user, then by default, the job runs with the container process owner (yarn), in this case be sure that user yarn has all the required permissions to run the job.
Example:
// cat spark.sh
/usr/odh/current/spark3-client/bin/spark-submit --master yarn --deploy-mode client --queue default --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.2.1.jar
// Application throws exception if yarn user doesn't have read permission to access spark-examples_2.12-3.2.1.jar.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=yarn, access=READ, inode="/workflow/lib/spark-examples_2.12-3.2.1.jar":hue:hdfs:---------x
In this case user yarn must have required permissions to include
spark-examples_2.12-3.2.1.jar
in the Spark job.
- If you submit a Spark job with a specific user (--proxy-user spark), then be sure that the Yarn user can impersonate that specified user. If the Yarn user can't impersonate the specified user and receives errors such as (
User: Yarn is not allowed to impersonate Spark), add the following configurations.
// cat spark.sh
/usr/odh/current/spark3-client/bin/spark-submit --master yarn --proxy-user spark --deploy-mode client --queue default --class
org.apache.spark.examples.SparkPi spark-examples_2.12-3.2.1.jar
In this case, the job is run using the Spark user. The Spark user must have access to all the related files (spark-examples_2.12-3.2.1.jar). Also, be sure the Yarn user can impersonate the Spark user. Add the following configurations so that the yarn user impersonate other users.
- Access Apache Ambari.
- From the side toolbar, under Services select HDFS.
- Select the Advanced tab and add the following parameters under Custom core-site.
- hadoop.proxyuser.yarn.groups = *
- hadoop.proxyuser.yarn.hosts = *
- Select Save and restart all the required services.
-
Run the Hive workflow from Oozie.
- Sign in to Hue.
- Create a script file and upload it to Hue.
- Sign in to Hue, and then in the leftmost navigation menu, select Scheduler.
- Workflow.
- Drag the third icon of HiveServer2 to the Drop your action here area.
- To select the Hive query script from HDFS, select the script menu. The query script is stored in an HDFS path that's accessible to the user that's signed in.
- To save the workflow, select the save icon.
- the run icon.