OpenSearchアラートおよび通知プラグインでの検索の使用
OpenSearchの組込みアラートおよび通知プラグインを使用して、クラスタのヘルス、パフォーマンス・メトリックおよび操作上の問題を監視します。
OpenSearchクラスタのサイズ設定と最適化は、パフォーマンスとコスト効率に不可欠です。時間の経過とともに、クラスタの使用パターンが変化し、過負荷、待機時間の増加またはエラーにつながる可能性があります。潜在的な問題をエスカレートする前に検出して軽減するには、予防的な監視とアラートが不可欠です。
OpenSearchには、このようなアラートの作成に役立つ組込みのアラートおよびモニタリング・プラグインがあります。このトピックでは、アラートの設定、Oracle Notificationサービス(ONS)との統合および一般的な問題の軽減に関するガイダンスを提供します。
OpenSearchアラート・プラグイン
アラート・プラグインは、OpenSearch内のイベントのモニタリングおよび通知を提供します。REST APIを使用して、クラスタおよびノードのメトリックに基づいて複雑なアラートを作成します。アラート・プラグインには、次の機能が含まれています。
- 連鎖モニター: 様々なREST API出力の複数の条件を組み合せて、複雑なアラートを作成します。
- 制御間隔: 通知の疲労を回避するためにアラートを評価する頻度を定義します。
- RBACサポート: アラートの管理にロールベースのアクセス制御を使用します。
OpenSearchモニタリングの詳細は、モニタリングに関する項を参照してください。
サポートされているメトリックおよびアラート
次のメトリックのアラート・プラグインを構成できます。
- クラスタのヘルス: ステータスが変化します(緑、黄、赤)。
- ノード・メトリック: ディスク使用率、CPU、JVMの負荷が高い。
- シャード・メトリック: 大きいシャード、過剰なシャード数。
- タスク・メトリック: スタックまたは拒否されたタスク、高いスクロール・タスク数。
- スロットル: 索引または問合せスロットル。
アラートの設定
次のOpenSearch APIの出力に対してアラートを設定できます。
- _クラスタ/ヘルス
- _cluster/stats
- _cluster/settings
- ノード/スタット(_N)
- _cat/インデックス
- _cat/pending_tasks
- _cat/リカバリ
- _cat/シャード
- _cat/スナップショット
- _cat/タスク
詳細は、クラスタごとのメトリック・モニターを参照してください。
OpenSearch通知プラグイン
通知プラグインを使用して、アラート・プラグインを使用して構成されたアラートに関する自動通知を取得します。Oracle Notification Service (ONS)は、通知プラグインと統合されています。構成されたONSトピックに通知を送信する通知プラグインを使用してチャネルを作成できます。その後、これらのチャネルをアラートにリンクして、起動アラートに関する通知を受信できます。
次に、アラート通知の例を示します:
Monitor Test index stats just entered alert status. Please investigate the issue.
- Trigger: test
- Severity: 2
- Period start: 2025-02-06-06T08:48:45.047Z
- Period end: 2025-02-06-06T08:49:45.047ZOpenSearch通知プラグインの詳細は、「通知」を参照してください。
Oracle Notification Service(ONS)
Oracle Cloud Infrastructure Notificationsサービス(ONS)は、パブリッシュ/サブスクライブ・パターンを介して、セキュアで信頼性の高いメッセージを分散コンポーネントにブロードキャストします。これは、Oracle Cloud Infrastructureおよび外部でホストされているアプリケーションに使用できます。ONSを使用して、イベント・ルールをトリガーしたとき、またはアラームに違反したときに通知されます。または、メッセージを直接公開します。
ONSでは、メッセージの配信用に次のチャネルがサポートされています。
- Eメール
- 関数
- HTTPエンドポイント(外部アプリケーション用)
- PagerDuty
- Slack
- SMS
OCI通知サービスの詳細は、通知を参照してください。
次の図は、ONSを使用した通知のブロードキャスト方法を示しています。
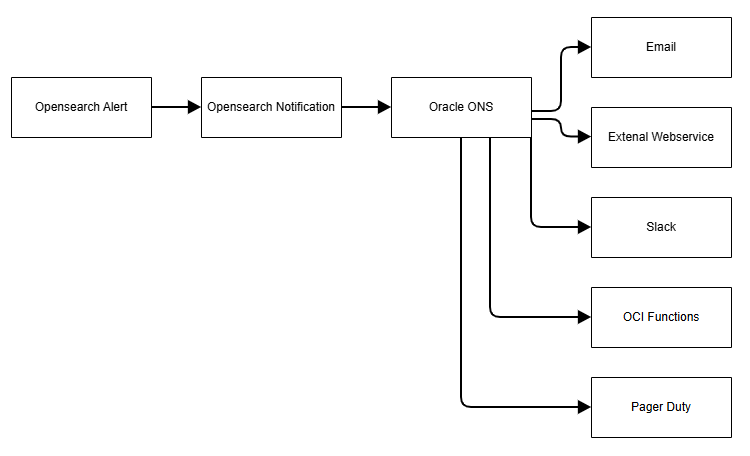
通知のあるアラートの例
アラートを作成して、OpenSearchクラスタのパフォーマンスに影響を与える可能性のあるOpenSearchのほとんどの重要な領域を監視できます。ベスト・プラクティスは、いくつかのパラメータが問題になることを示す警告レベルのアラートを設定することです。これにより、OpenSearchクラスタが不適切な状態になる前に修正処理を実行できます。
次の項では、OpenSearchクラスタで設定できる警告レベルとエラー・レベルの両方のアラートについて説明します。
通知チャネル
アラートを作成する前に、通知チャネルを設定することをお薦めします。ONSチャネルのサブスクリプションを使用すると、電子メール、Slack、OCI関数、ストリームなど、様々な通信方法で自動通知を取得できます。
次の例では、通知チャネルの作成方法を示します。
{
"config_id": "sample-id",
"name": "test-ons1",
"config": {
"name": "test-ons1",
"description": "send notifications",
"config_type": "ons",
"is_enabled": true,
"ons": {
"topic_id": "ocid1.onstopic.oc1.iad.amaaaaaawtpq47yar24xitgso2wble2a5shal52r6zoc6eyth3jzsmbvxspa"
}
}
}クラスタ・ヘルス
OpenSearchクラスタの状態は次のとおりです。
- 緑色: 使用可能なすべてのシャード。
- 黄色: 一部のレプリカ・シャードが使用できません。使用可能なレプリカが少ないため、パフォーマンスが低下する可能性があります。
- 赤: 一部のプライマリ・シャードが使用できません。赤は、データが使用できないことを示し、使用できないシャードへの問合せが失敗します。
黄色のクラスタアラートの構成
次の構成を使用して、クラスタのイエロー・アラートを設定します。
POST: {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthYellow",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"yellow\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}黄色のクラスタアラートの構成
次の構成を使用して、クラスタのレッド・アラートを設定します。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthRed",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"red\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}ノード数
次の構成を使用して、クラスタのノード数を指定します。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterNodesUnavailable",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check all nodes available",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].number_of_nodes< 8",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}問題のトラブルシューティング
リストアの失敗、ノードが一時的に切断されたり、ディスクがいっぱいになったりするなど、様々な理由により、クラスタの健全性が黄色または赤になる可能性があります。一部の問題はOCI OpenSearchチームで修正する必要がありますが、他の問題は自分でトラブルシューティングして修正できます。
スワップ方法:
- キャット・シャードAPIを使用してすべてのシャードのリストを取得し、未割当てのシャードを確認します。
- OpenSearchクラスタが赤の場合:
- CAT割当てAPIを使用して、未割当てシャードの割当て理由を確認します。
- 問題が一時的であり、緩和されている場合は、強制再ルーティングAPIを使用してシャードの再割当てを試行します。
- シャードの割当ての説明でリストア試行の失敗が示されている場合は、クラスタを以前の正常な状態にリストアします。
- それでも問題が解決しない場合は、OCI OpenSearchチームに連絡してください。
- OpenSearchクラスタが黄色の場合:
- ノード数が索引の最大レプリカ数以上かどうかを確認します。
- CAT割当てAPIを使用して、未割当てシャードの割当て理由を確認します
- 問題が一時的なものと思われる場合は、強制再ルーティングAPIを使用してシャードを再割当てします。
クラスタ内の1つ以上のノードが長期間使用できない場合は、OCI OpenSearchチームに連絡してください。これらの症状は、基盤となるインフラストラクチャに問題がある可能性があることを示しています。
ノード・レベル統計
すべてのOpenSearchノードが最適に機能するためには、CPU、RAMおよびディスク領域など、すべての基本メトリックに関して適切なバッファが必要です。これらのメトリックのクリティカル・レベルに到達すると、レイテンシが減少し、遅延が増大し、最終的にノードがハングしたりクラスタから離れることになります。
次のメトリックに2つのレベルのアラートを設定できます。1つは警告レベル用、もう1つはクリティカル・レベル用です。
高ディスク/CPU/JVM
警告レベル
次の構成を使用して、OpenSearchノードの警告レベル・アラートを指定します。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 70) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}クリティカル・レベル
次の構成を使用して、OpenSearchノードのクリティカル・レベル・アラートを指定します。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 85) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}トラブルシューティング
ディスク使用率が高い場合は、ディスク・サイズを増やすか、古いデータをパージするようにISMポリシーを設定してください。
トラフィックおよびノード構成を確認します。クラスタが長時間ノード・パラメータのために負荷がかかっている場合は、通常、構成不足のクラスタを示します。
保留中のタスク
保留中のタスクのリストでは、どのOpenSearchタスクがどのノードで実行されるかを指定します。OpenSearchタスクのほとんどは、再索引付け操作のようなもの以外は、OpenSearchが大きな作業から分割された小さなタスクです。
次の構成を使用して、OpenSearchノードの保留中のタスクをリストします。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "pending_tasks",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"enabled_time": 1746584774661,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_TASKS",
"path": "_cat/tasks",
"path_params": "",
"url": "http://localhost:9200/_cat/tasks",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "jUOQqJYBQxJTy-1pqNIF",
"name": "test",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].tasks){\n\nif(item.running_time_in_nanos> 300000000000) return true;\n}\nreturn false\n",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false
}トラブルシューティング
保留中のタスクは、ノードの過負荷、ノードの不正な状態、またはタスクの不正なパラメータを示すことができます。保留中のノードに関連する問題をトラブルシューティングするには、次のガイダンスを使用します。
- クラスタで複数のタイプのマージまたはバルク索引を実行している場合は、強制マージを実行して、すべてを1つのアクションでマージするため問題を解決します。
- クラスタでクラスタの更新設定がスタックしている場合、ノードまたはノードのキューの状態に問題がある可能性があります。スタックしたタスクを削除するか、ノードを再起動して問題を修正してください。
- クラスタでタイプ・スナップショットがスタックしている場合、リポジトリに問題がある可能性があります。リポジトリ設定を確認します。エラーが自動バックアップに関連している場合は、OCI OpenSearchチームに連絡してください。
却下されたタスクおよびスレッド
拒否されたスレッドは、タスク間の高レベルのスロットルを示します。たとえば、アクティビティが多すぎて、処理できない多くの索引および検索リクエストがかわりにスロットルされる場合があります。
次の構成を使用して、拒否されたタスクおよびスレッドをリストします。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Rejected threads",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "1kNRrpYBQxJTy-1pGtJ9",
"name": "rejected thread pool",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{\n for (e in entry.getValue().thread_pool.entrySet()) {\n if(e.getValue().rejected>10){\n return true;\n}\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}トラブルシューティング
却下されたタスクは、システムの過負荷を示す場合があります。否認されたタスクのタイプでレビューします。これらのタスクのトラフィックを削減できるか、タスクの設定/構造が変更されたかを確認します。
Search関数がスロットルされている場合は、検索問合せを最適化できるかどうかを確認します。
索引付けファンクションがスロットルされている場合は、索引作成またはバルク設定のレートを更新できるかどうか、または索引とシャードを小さなタスクに分割できるかどうかを確認します。
索引レベル統計
シャード・サイズ
索引データは、シャードと呼ばれる独立した構造に格納されます。すべてのシャードはセグメントで構成され、セグメントはSearch関数を支援するためにOpenSearchメモリーにロードされます。30-50 GB以上のシャードではセグメントが大きくなり、メモリー使用量が増加します。パフォーマンスをクラスタ化するには、シャードのサイズを正しく設定することが重要です。シャード・サイズは、通常、索引ライフサイクル管理(ILM)ポリシーによって制御できます。ILMを持たない索引の場合、索引が大きくなりすぎないように、シャード・サイズにアラートを設定できます。
次の構成を使用して、シャードとそのサイズをリストします:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Big shard size",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_SHARDS",
"path": "_cat/shards",
"path_params": "",
"url": "http://localhost:9200/_cat/shards",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "pkOWqJYBQxJTy-1pO9Im",
"name": "big shards",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].shards)\nif((item.store != null)&&(item.store.contains(\"gb\"))&&(item.store.length()>4)\n&&(Double.parseDouble(item.store.substring(0,item.store.length()-3))>30)) return true\n",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false
}トラブルシューティング
古いインデックス作成
データがクラスタに索引付けされると、OpenSearchは最初にデータをトランスログ・ファイルに書き込みます。次に、OpenSearchプロセスは、このファイルからエントリを定期的に取得して、Apache Lucene構造にデータを取り込み、トークン化子、フィールド・データなどの必要な内部オブジェクトを含む適切なセグメントを作成します。取込み率が高いか、クラスタが不足していると、取込みプロセスの遅れが発生する可能性があります。ここでは、トランスログ・ファイル・サイズが、ドキュメントの索引付けのラグとともに大きくなります。この動作は、索引付け統計を使用して監視できます。
索引の遅延を監視するには、次の構成を使用します。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "UncommittedSize large",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Uncommited size",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.translog.uncommitted_size_in_bytes>1000000000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}トラブルシューティング
遅延索引付けのトラブルシューティングを行う場合は、次のタスクを実行します。
- 索引付け圧力を確認します。
- CPU、メモリー、ディスクIO統計などの他のノード統計を確認します。
前述のタスクの結果に基づいて、次のオプションを検討してください。
- インデックス作成の圧力を減らします。
- ノードの構成を増やします。
- トランスログがあまり高くない場合は、refresh_intervalを増やします。
スロットル
OpenSearchは、Luceneセグメントの形式でデータを格納します。セグメントは、同じドキュメント上の多くの操作を照合するために、継続的に凝縮およびマージされます。必要な索引付け速度がOpenSearchクラスタが対応できる速度より大きい場合、これらのマージは調整されます。索引付け統計を使用してスロットルを監視し、要件を満たすようにスロットルしきい値を更新できます。
スロットルを設定するには、次の構成を使用します。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Merge Throttling",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "Merge Throttling",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.merges.total_throttled_time_in_millis>300000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}
トラブルシューティング
スロットルをトラブルシューティングする場合は、次のタスクを実行します。
- 索引付け圧力を確認します。
- CPU、メモリー、ディスクIO統計などの他のノード統計を確認します。
前述のタスクの結果に基づいて、次のオプションを検討してください。
- インデックス作成の圧力を減らします。
- ノードの構成を増やします。
- トランスログがあまり高くない場合は、refresh_intervalを増やします。
検索
スクロール
多くの結果が期待される場合、スクロールによる検索が使用されます。ただし、あまりにも多くのスクロールを使用すると、OpenSearchのメモリーが使用されます。これは、コンテキストを維持する必要があり、パフォーマンスが低下するためです。fアラートを使用すると、常に開いているスクロール数のタブを保持できます。
次の構成を使用して、常に開いているスクロールの数を追跡します。
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Large Number of Open Scrolls",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Open Scrolls",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.search.scroll_current>200) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}