データ・フローの管理
アプリケーション実行のチューニング方法、パフォーマンスの最適化、オブジェクト・ストレージ・アクセスのチューニング方法、Sparkパフォーマンスのベスト・プラクティス、および一般的な問題のトラブルシューティングと修正方法など、データ・フローの管理方法について学習します。
データ・フロー実行のチューニング
チューニングの概要
データ・フローで実行するSparkアプリケーションをチューニングする前に、Sparkアプリケーションの実行方法を理解することが重要です。Sparkアプリケーションを実行すると、選択したVMのシェイプおよび数に基づいてVMのクラスタがプロビジョニングされます。Sparkはこのクラスタ内で実行されます。これらのVMはSparkアプリケーション専用ですが、共有のマルチテナント・ハードウェアおよびソフトウェア環境内で実行されます。
アプリケーションを起動する際、「ドライバ」に1つのVMシェイプ・タイプを選択し、「ワーカー」に別のシェイプを選択します。また、必要なワーカーの数も指定します。常に一人のドライバーしかいない。ドライバとワーカーは、VM内のすべてのCPUリソースおよびメモリー・リソースを消費するように自動的にサイズ設定されます。ワークロードでより大きいまたは小さいJava仮想マシンが必要な場合、大きいまたは小さいVMインスタンス・タイプを選択して、これを制御できます。
データ・フローは、Oracle Object Storageの使用を単純かつ透過的にするように設計されています。この結果、オブジェクト・ストレージは、常に、パフォーマンスの低いアプリケーションを検査するときに最初に調査する必要があるものの1つです。
パフォーマンスの最適化
特にアプリケーションがすでに最適化されている場合、問題の発生時にリソースをさらにスローすることが最善の方法である場合があります。データ・フローを使用すると、すべてのSparkアプリケーションの実行時履歴をトラッキングし、1箇所で集中管理できます。データ・フローUI内で、最適化するアプリケーションをロードします。「アプリケーションの詳細」画面には、実行の履歴およびその実行中に使用されたリソースが表示されます。多くの場合、SLAを打つことは、追加のCPUおよびメモリー・リソースを使用するのと同じくらい簡単です。 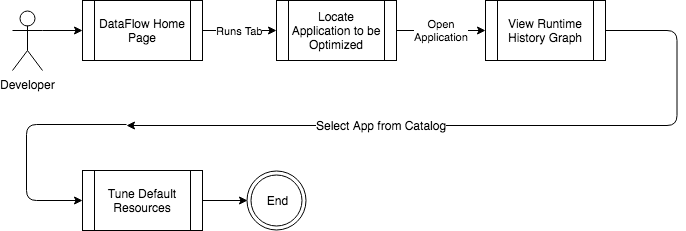
オブジェクト・ストレージへのアクセスのチューニング
オブジェクト・ストレージは、すべてのOracle Cloud Infrastructureデータ・センターにデプロイされます。Sparkアプリケーションが、データが格納されている同じOracle Cloud Infrastructureリージョンで実行されている場合、オブジェクト・ストレージへのアクセスは非常にパフォーマンスが高くなります。データの読取りまたは書込みが遅い場合は、データと同じリージョンでデータ・フロー・アプリケーションを開いていることを確認してください。アクティブなリージョンは、Oracle Cloud InfrastructureのUIで表示できます。REST APIも、特定のリージョンにターゲット指定する必要があります。
Sparkのパフォーマンスのベスト・プラクティス
- オブジェクト・ストレージを使用します。オブジェクト・ストレージでは、RDBMSからデータを読み取るよりも大幅に広い帯域幅が提供されます。オブジェクト・ストレージにデータを事前にコピーすると、処理が大幅に高速化されます。
- 可能な場合は必ず、Parquetfileを使用します。Parquetfileは最大10分の1の大きさで、ジョブではファイル全体ではなく必要なデータのみを読み取ります
- データセットを適切にパーティション化します。ほとんどの分析アプリケーションは、最後の週のデータなどにアクセスするだけです。最近のデータが古いデータから分離したファイルになるようにデータをパーティション化してください。
- Spark UI内で長時間実行されるエグゼキュータを検索することにより、データの偏りの問題を特定します。
- ドライバのボトルネックを回避します。Spark内のデータを収集すると、すべてのデータがSparkドライバに戻されます。ジョブでは収集操作をできるだけ遅く実行します。大きいデータセットを収集する必要がある場合は、より大きいVMシェイプまでドライバ・ノードをスケーリングすることを検討してください。これにより、十分なメモリーおよびCPUリソースを確保できます。
- Oracle Cloud Infrastructureコンソールで、「ガバナンス」に移動します。
- 「制限、割当ておよび使用状況」を選択します。
- 割当てを増やすには、「サービス制限の引上げのリクエスト」をクリックします。
- (推奨) CI/CDパイプラインの終了時にSparkコードをOracle Cloud Infrastructureにアップロードします。この方法を使用する場合、バックアップは他の場所で処理されるため、Sparkアプリケーションをバックアップする必要はありません。
- コードを手動で管理する場合は、多くのリージョンにコピーします。
主な考慮事項は、リージョナル・フェイルオーバーです。この発生を準備するには、多くのリージョンにデータ・フロー・アプリケーションを作成し、リージョン間でデータを同期します。その後、リージョン・フェイルオーバーは、別のリージョン内のデータ・フローAPIを正しい構成で呼び出すことになります。アプリケーションOCIDは、各リージョンで異なります。
ジョブに関する一般的な問題
データ・フロー・ジョブは多くの理由で失敗しますが、通常、次の原因が考えられます:
- アプリケーション・エラー。
- メモリー不足エラー。
- 一時的な実行時の問題。
- Logs from Oracle Cloud Infrastructure Logging are available if you have followed the steps to Enable Oracle Cloud Infrastructure Logging Logs in Data Flow.
- Spark UI。
- Sparkログ(Sparkドライバおよびすべてのエグゼキュータの
stdoutおよびstderrストリーム)。
これらはどちらも、問題の「実行」をロードすることで、ブラウザから安全にアクセスします。

ジョブが失敗した場合は、最初にドライバのstderrログ・ファイルを確認します。ほとんどのエラーがここに表示されます。次に、エグゼキュータのstderrログ・ファイルを確認します。ログ・ファイルに特定のエラーがない場合は、Spark UIをロードしてSparkアプリケーションをさらに調査できるようにします。
- ソースでアプリケーション・エラーを修正する必要があります。その後、新規アプリケーションを作成できます。
- より大きいインスタンスを実行したり、きめ細かなパーティション化を経由してより小さいデータを処理したり、あるいはアプリケーションをより効率的にするために最適化することにより、メモリー不足エラーに対処します。
- データ・フローは、一時的な実行時の問題から保護しようとします。エラーが続く場合は、Oracleサポートに連絡してください。
- 無効なリクエストによって不正なリクエスト・エラーが返され、それをログ・ファイルで確認できます。
- ユーザーに権限がない(リクエストは有効である)場合は、
Not Authorizedエラーが返されます。