ライセンス持込みコンテナ
モデル・デプロイメントの作成時に、カスタム・コンテナ(Bring Your Own ContainerまたはBYOC)を実行時の依存性として使用します。
カスタム・コンテナを使用すると、システムおよび言語の依存関係をパッケージ化し、推論サーバーをインストールおよび構成し、様々な言語実行時間を設定できます。コンテナを実行するためのモデル・デプロイメント・リソースを持つインタフェースの定義済境界内のすべてのもの。
BYOCを使用すると、異なる環境間でコンテナを転送できるため、アプリケーションをOCI Cloudに移行およびデプロイできます。
ジョブを実行するには、Dockerfileを作成してからイメージを作成する必要があります。Pythonイメージを使用するDockerfileから開始します。Dockerfileは、ローカルおよびリモートのビルドを作成できるように設計されています。ローカル・ビルドは、コードに対してローカルでテストするときに使用します。ローカル開発中、コードの変更ごとに新しいイメージを作成する必要はありません。
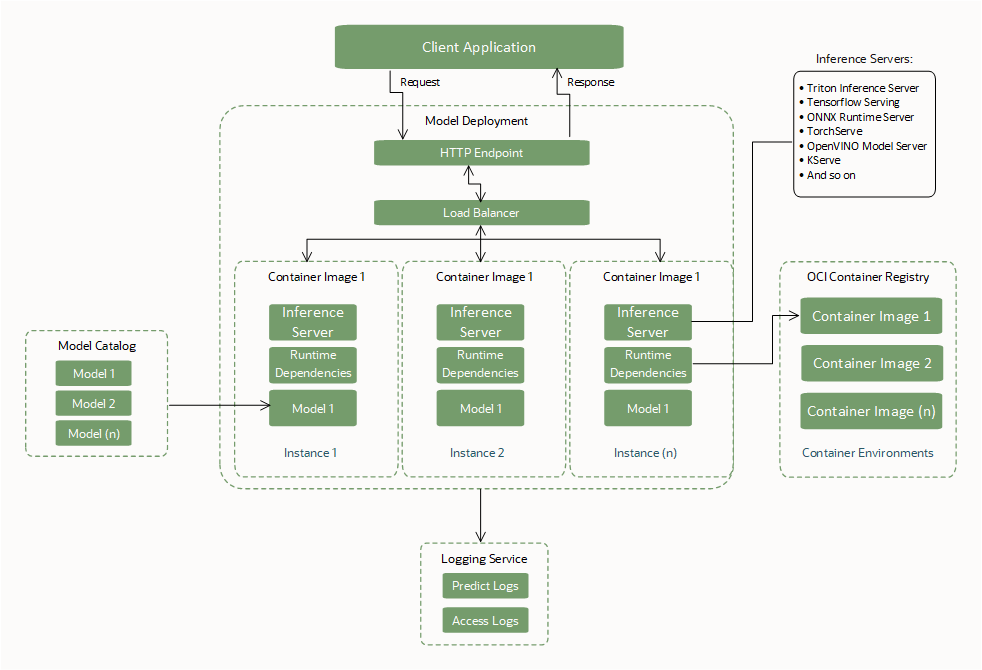
BYOC必須インタフェース
モデル・デプロイメントを使用するには、これらの必須インタフェースを作成または指定します。
モデル・アーティファクト
| Interface | 説明 |
|---|---|
| データ・サイエンス・モデル・カタログにモデル・アーティファクトをアップロードします。 | モデル・デプロイメント・リソースで使用する前に、スコアリング・ロジック、MLモデル、依存ファイルなどのモデル・アーティファクトをデータ・サイエンス・モデル・カタログにアップロードする必要があります。 |
| 必須ファイルがありません。 |
BYOCモデル・デプロイメントの作成に必須のファイルはありません。 ノート:モデル・デプロイメントにBYOCを使用しない場合でも、 |
| マウントされたモデル・アーティファクトの場所。 |
ブートストラップ・モデルのデプロイメント中に、モデル・アーティファクトを解凍し、実行中のコンテナ内の 一連のファイル(MLモデルおよびスコアリング・ロジックを含む)またはファイル・セットを含むフォルダを圧縮すると、コンテナ内のMLモデルへの場所パスが異なります。スコアリング・ロジックでモデルをロードするときに、正しいパスが使用されていることを確認します。 |
コンテナ・イメージ
| Interface | 説明 |
|---|---|
| パッケージ・ランタイムの依存性。 | MLモデル・バイナリをロードおよび実行するために必要なランタイム依存性をコンテナ・イメージにパッケージ化します。 |
| エンドポイントを公開するWebサーバーをパッケージ化します。 |
HTTPベースのステートレスWebサーバー(FastAPI、Flask、Triton、TensorFlowサービス、PyTorchサービスなど)でコンテナ・イメージをパッケージ化します。
ノート: データ・サイエンス・エンドポイント・インタフェースを満たすように推論サーバーのエンドポイントをカスタマイズできない場合は、プロキシ(NGINXなど)を使用して、サービス必須エンドポイントをフレームワークによって提供されるエンドポイントにマップします。 |
| 公開されたポート。 |
ポートは1024から65535に制限されています。ポート24224、8446、および8447は除外されます。提供されたポートはサービスによってコンテナに公開されるため、Dockerファイルで再度公開する必要はありません。 |
| イメージのサイズ | コンテナ・イメージのサイズは、非圧縮形式では16 GBに制限されます。 |
| イメージへのアクセス。 | モデル・デプロイメントを作成する演算子は、使用するコンテナ・イメージにアクセスできる必要があります。 |
| Curlパッケージ。 | Docker HEALTHCHECKポリシーが成功するには、curlパッケージをコンテナ・イメージにインストールする必要があります。オープンな脆弱性がない最新の安定した curlコマンドをインストールします。 |
CMD, Entrypoint |
docker CMDまたはEntrypointは、WebサーバーをブートストラップするAPIまたはDockerファイルを使用して指定する必要があります。 |
CMD、Entrypointサイズ。 |
CMDとEntrypointを組み合せたサイズは、2048バイトを超えることはできません。サイズが2048バイトを超える場合は、モデル・アーティファクトを使用してアプリケーション引数を指定するか、オブジェクト・ストレージを使用してデータを取得します。 |
一般的な推奨事項
| 推奨事項 | 説明 |
|---|---|
| モデル・アーティファクトにMLモデルをパッケージ化します。 |
MLモデルをアーティファクトとしてパッケージ化し、データ・サイエンス・モデル・カタログにアップロードして、モデル・ガバナンスおよびモデル・バージョニング機能を使用しますが、コンテナ・イメージにMLモデルをパッケージ化するオプションがあります。モデル・カタログへのモデルの保存 モデルがモデル・カタログにアップロードされ、モデル・デプロイメントの作成時に参照されると、データ・サイエンスはアーティファクトのコピーをダウンロードし、スコアリング・ロジックが消費されるように |
| すべての操作のイメージおよびイメージ・ダイジェストを指定します | イメージの使用の一貫性を維持するために、モデル・デプロイメント操作を作成、更新およびアクティブ化するイメージおよびイメージ・ダイジェストを提供することをお薦めします。別のイメージへの更新操作では、イメージとイメージ・ダイジェストの両方が、予想されるイメージに更新するために不可欠です。 |
| 脆弱性スキャン | OCIの脆弱性スキャン・サービスを使用して、イメージ内の脆弱性をスキャンすることをお薦めします。 |
| APIフィールドがnullです | APIフィールドが空の場合は、空の文字列、空のオブジェクトまたは空のリストを渡さないでください。明示的に空のオブジェクトとして渡す場合を除き、フィールドをnullとして渡すか、まったく渡さないでください。 |
BYOCのベスト・プラクティス
- モデル・デプロイメントでは、OCIレジストリに存在するコンテナ・イメージのみがサポートされます。
- コンテナ・イメージが、モデル・デプロイメントのライフサイクル全体でOCIレジストリに存在することを確認します。インスタンスが自動的に再起動する場合、またはサービス・チームがパッチ適用を実行する場合に、可用性を確認するためにイメージが存在する必要があります。
- BYOCでは、dockerコンテナのみがサポートされています。
- データ・サイエンスは、圧縮されたモデル・アーティファクトを使用してMLモデル・スコアリング・ロジックを持ち込み、データ・サイエンス・モデル・カタログで使用可能であることを期待します。
- コンテナ・イメージのサイズは、非圧縮形式では16 GBに制限されます。
- データ・サイエンスは、コンテナを起動する前に
HEALTHCHECKタスクを追加するため、HEALTHCHECKポリシーはオーバーライドされるため、Dockerファイルに明示的に追加する必要はありません。ヘルス・チェックは、コンテナの起動後10分後に実行を開始し、30秒ごとに/healthをチェックし、タイムアウトは3秒、再試行は1チェックにつき3回です。 - Docker
HEALTHCHECKポリシーが成功するには、curlパッケージをコンテナ・イメージにインストールする必要があります。 - モデル・デプロイメント・リソースを作成するユーザーは、それを使用するにはOCIレジストリのコンテナ・イメージにアクセスできる必要があります。そうでない場合は、モデル・デプロイメントを作成する前に、ユーザー・アクセスIAMポリシーを作成します。
- docker
CMDまたはEntrypointは、WebサーバーをブートストラップするAPIまたはDockerfileを介して指定する必要があります。 - コンテナの実行に対するサービス定義タイムアウトは10分であるため、この時間枠内に推論提供コンテナが開始(正常)されるようにします。
- モデル・デプロイメントを使用してクラウドにデプロイする前に、常にコンテナをローカルでテストしてください。
Dockerイメージ・ダイジェスト
Dockerレジストリ内のイメージは、リポジトリ、名前およびタグによって識別されます。さらに、Dockerでは、イメージの各バージョンに一意の英数字のダイジェストが付与されます。更新されたDockerイメージをプッシュする場合は、既存のタグを再利用せずに、更新されたイメージに特定するための新しいタグを提供することをお薦めします。ただし、更新されたイメージをプッシュして、そのイメージに以前のバージョンと同じ名前およびタグを付ける場合でも、新しくプッシュされたバージョンのダイジェストは、以前のバージョンとは異なります。
モデル・デプロイメント・リソースを作成する場合は、モデル・デプロイメントの基礎となる特定のバージョンのイメージの名前とタグを指定します。不整合を回避するために、モデル・デプロイメントでは、そのバージョンのイメージの一意のダイジェストが記録されます。モデル・デプロイメントの作成時にイメージのダイジェストを指定することもできます。
デフォルトでは、モデル・デプロイメントのベースとなるイメージの元のバージョンと同じ名前およびタグを使用して、更新されたバージョンのイメージをDockerレジストリにプッシュすると、元のダイジェストを使用してイメージの元のバージョンがプルされます。モデル・デプロイメントでイメージの最新バージョンをプルする場合は、プルするイメージのバージョンを識別するためにモデル・デプロイメントが使用するタグおよびダイジェストを使用してイメージ名を明示的に変更できます。
モデル・アーティファクトの準備
アーティファクトzipファイルを作成し、モデルとともにモデル・カタログに保存します。アーティファクトには、コンテナを操作して推論リクエストを実行するコードが含まれています。
コンテナは、推論サーバーのヘルスを返す/healthエンドポイントと、推論を行うための/predictエンドポイントを公開する必要があります。
モデル・アーティファクトの次のPythonファイルは、ポート5000のFlaskサーバーを使用してこれらのエンドポイントを定義します:
# We now need the json library so we can load and export json data
import json
import os
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neural_network import MLPClassifier
import pandas as pd
from joblib import load
from sklearn import preprocessing
import logging
from flask import Flask, request
# Set environnment variables
WORK_DIRECTORY = os.environ["WORK_DIRECTORY"]
TEST_DATA = os.path.join(WORK_DIRECTORY, "test.json")
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE_LDA = os.environ["MODEL_FILE_LDA"]
MODEL_PATH_LDA = os.path.join(MODEL_DIR, MODEL_FILE_LDA)
# Loading LDA model
print("Loading model from: {}".format(MODEL_PATH_LDA))
inference_lda = load(MODEL_PATH_LDA)
# Creation of the Flask app
app = Flask(__name__)
# API 1
# Flask route so that we can serve HTTP traffic on that route
@app.route('/health')
# Get data from json and return the requested row defined by the variable Line
def health():
# We can then find the data for the requested row and send it back as json
return {"status": "success"}
# API 2
# Flask route so that we can serve HTTP traffic on that route
@app.route('/predict',methods=['POST'])
# Return prediction for both Neural Network and LDA inference model with the requested row as input
def prediction():
data = pd.read_json(TEST_DATA)
request_data = request.get_data()
print(request_data)
print(type(request_data))
if isinstance(request_data, bytes):
print("Data is of type bytes")
request_data = request_data.decode("utf-8")
print(request_data)
line = json.loads(request_data)['line']
data_test = data.transpose()
X = data_test.drop(data_test.loc[:, 'Line':'# Letter'].columns, axis = 1)
X_test = X.iloc[int(line),:].values.reshape(1, -1)
clf_lda = load(MODEL_PATH_LDA)
prediction_lda = clf_lda.predict(X_test)
return {'prediction LDA': int(prediction_lda)}
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0', port = 5000)
コンテナの構築
OCIコンテナ・レジストリから任意のイメージを使用できます。次に、Flaskサーバーを使用するサンプルDockerfileを示します。
FROM jupyter/scipy-notebook
USER root
RUN \
apt-get update && \
apt-get -y install curl
ENV WORK_DIRECTORY=/opt/ds/model/deployed_model
ENV MODEL_DIR=$WORK_DIRECTORY/models
RUN mkdir -p $MODEL_DIR
ENV MODEL_FILE_LDA=clf_lda.joblib
COPY requirements.txt /opt/requirements.txt
RUN pip install -r /opt/requirements.txtdocker HEALTHCHECKポリシーが機能するには、Curlパッケージをコンテナ・イメージにインストールする必要があります。
Dockerfileと同じディレクトリに次のパッケージを含むrequirements.txtファイルを作成します。
flask
flask-restful
joblibdocker buildコマンドを実行します。
docker build -t ml_flask_app_demo:1.0.0 -f Dockerfile .モデル・デプロイメントで使用できる解凍済コンテナ・イメージの最大サイズは16 GBです。コンテナ・イメージのサイズはコンテナ・レジストリからプルされるため、モデル・デプロイメントのプロビジョニング時間が遅くなることに注意してください。可能なかぎり最小のコンテナ・イメージを使用することをお薦めします。
コンテナのテスト
モデル・アーティファクトと推論コードがDockerfileと同じディレクトリにあることを確認します。ローカル・マシンでコンテナを実行します。ローカル・モデル・ディレクトリを/opt/ds/model/deployed_modelにマウントして、ローカル・マシンに格納されているファイルを参照する必要があります。
docker run -p 5000:5000 \
--health-cmd='curl -f http://localhost:5000/health || exit 1' \
--health-interval=30s \
--health-retries=3 \
--health-timeout=3s \
--health-start-period=1m \
--mount type=bind,src=$(pwd),dst=/opt/ds/model/deployed_model \
ml_flask_app_demo:1.0.0 python /opt/ds/model/deployed_model/api.pyヘルス・リクエストを送信して、コンテナが10分以内に実行されていることを検証します:
curl -vf http://localhost:5000/health予測リクエストを送信してテストします。
curl -H "Content-type: application/json" -X POST http://localhost:5000/predict --data '{"line" : "12"}'OCIコンテナ・レジストリへのコンテナのプッシュ
Oracle Cloud Infrastructure Registry (コンテナ・レジストリとも呼ばれる)に対してイメージをプッシュおよびプルする前に、Oracle Cloud Infrastructureの認可トークンが必要です。認証トークン文字列は作成時にのみ表示されるため、認証トークンを安全な場所にコピーします。
- コンソールで詳細を表示するには: ナビゲーション・バーで、「プロファイル」メニューを選択し、表示されるオプションに応じて、「ユーザー設定」または「マイ・プロファイル」を選択します。
- 「認証トークン」ページで、「トークンの生成」を選択します。
- 認証トークンのわかりやすい説明を入力します。機密情報を入力しないでください。
- 「トークンの生成」を選択します。新しい認証トークンが表示されます。
- 認証トークンをすぐに安全な場所にコピーし、後で取り出せるようにします。コンソールに認証トークンが再び表示されることはありません。
- 「トークンの生成」ダイアログを閉じます。
- ローカル・マシンでターミナル・ウィンドウを開きます。
- コンテナ・イメージを構築、実行、テスト、タグ付けおよびプッシュできるように、コンテナ・レジストリにサインインします。
docker login -u '<tenant-namespace>/<username>' <region>.ocir.io - ローカル・コンテナ・イメージをタグ付けします:
docker tag <local_image_name>:<local_version> <region>.ocir.io/<tenancy_ocir_namespace>/<repository>:<version> - コンテナ・イメージをプッシュします:
docker push <region>.ocir.io/<tenancy>/byoc:1.0ノート
モデル・デプロイメント・リソースに、イメージを格納したコンパートメントからOCIレジストリからイメージを読み取ることができるように、リソース・プリンシパルのポリシーがあることを確認します。リソース・プリンシパルを使用したカスタム・コンテナへのモデル・デプロイメント・アクセス権の付与
モデル・デプロイメントを作成するときに、このコンテナ・イメージをBYOCオプションとともに使用する準備ができました。
BYOCモデルのデプロイメントでは、クロスリージョン・コンテナ・イメージのプルはサポートされていません。たとえば、IAD (アッシュバーン)リージョンでBYOCモデル・デプロイメントを実行する場合、PHX (フェニックス)リージョンのOCIR (Oracle Cloud Container Registry)からコンテナ・イメージをプルすることはできません。
BYOC更新操作の動作
BYOC更新操作は、浅いマージ・タイプの部分更新です。
書込み可能な最上位レベルのフィールドは、リクエスト・コンテンツに定義されている場合に完全に置換し、それ以外の場合は変更せずに保持する必要があります。たとえば、次のようなリソースの場合:
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 5454,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"environmentVariables": {
"a": "b",
"c": "d",
"e": "f"
},
"entrypoint": [ "python", "-m", "uvicorn", "a/model/server:app", "--port", "5000","--host","0.0.0.0"]
"cmd": ["param1"]
}次を使用した正常な更新:
{
"environmentConfigurationDetails": {
"serverPort": 2000,
"environmentVariables": {"x":"y"},
"entrypoint": []
}
}serverPortおよびenvironmentVariablesが更新コンテンツによって上書きされる状態になります(更新コンテンツにないディープ・フィールドに以前存在していたデータの破棄を含む)。imageは更新コンテンツに表示されなかったため変更せずに保持され、entrypointは明示的な空のリストによってクリアされます。
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 2000,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"environmentVariables": {"x": "y"},
"entrypoint": []
"cmd": ["param1"]
}{ "environmentConfigurationDetails": null or {} }を使用して正常に更新されると、何も上書きされません。最上位レベルの完全な置換では、リクエスト・コンテンツに存在しないすべての値が消去されるため、このことは避けてください。更新オブジェクトのすべてのフィールドはオプションであるため、イメージを指定しない場合は、デプロイメントでイメージを設定解除しないでください。データ・サイエンスは、第2レベルのフィールドがnullでない場合にのみ置換を行います。
リクエスト・オブジェクトにフィールドを設定しない(nullを渡す)ことは、既存のフィールド値との差異および置換を見つけるために、データ・サイエンスがそのフィールドを考慮しないことを意味します。
任意のフィールドの値をリセットするには、空のオブジェクトを渡します。リストおよびマップ・タイプのフィールドの場合、データ・サイエンスでは、値を消去するインジケーションとして空のリスト([])またはマップ({})を受け入れることができます。いずれの場合も、nullは値を消去することを意味しません。ただし、他の値にはいつでも変更できます。デフォルト・ポートを使用し、そのフィールド値を設定解除するには、デフォルト・ポートを明示的に設定します。
リストおよびマップ・フィールドへの更新は完全な置換です。データ・サイエンスは、オブジェクト内で個々の値を検索しません。
イメージおよびダイジェストの場合、データ・サイエンスでは値を消去できません。
トリトン推論サーバー・コンテナを使用したデプロイ
NVIDIA Triton Inference Serverは、チームがGPUまたはCPUベースのインフラストラクチャ上の任意のフレームワークからトレーニング済みのAIモデルを導入、実行、拡張できるようにすることで、AI推論を合理化および標準化します。
Tritonの主な機能は次のとおりです。
- 同時モデル実行:複数のMLモデルを同時に提供する機能。この機能は、単一のシステムで一緒にデプロイおよび管理する必要があるモデルが複数ある場合に役立ちます。
- 動的バッチ処理:サーバーがワークロードに基づいてリクエストを動的にまとめてバッチ処理できるようにすることで、パフォーマンスが向上します。
モデル・デプロイメントでは、NVIDIA Triton Inference Serverが特別にサポートされています。NVIDIAのコンテナ・カタログから既存のTritonイメージをデプロイでき、モデル・デプロイメントでは、モデル・デプロイメントの作成時に次の環境変数を使用してコンテナ内の何も変更する必要なく、Tritonインタフェースが一致することが保証されます。
CONTAINER_TYPE = TRITONONNXモデルをTritonにデプロイする方法に関する完全な文書化されたサンプルは、データ・サイエンス・モデル・デプロイメントGitHubリポジトリにあります。