Query External Data with AWS Glue Data Catalog
Autonomous AI Database supports a system for synchronizing with an Amazon AWS Glue Data Catalog instance.
About Querying with AWS Glue Data Catalog
Autonomous AI Database allows you to synchronize with Amazon Web Service (AWS) Glue Data Catalog metadata. A database external table is automatically created by Autonomous AI Database for every table harvested by AWS Glue about data stored in Amazon Simple Storage Service (S3). Users can query data stored in S3 from Autonomous AI Database without having to manually derive the schema for the external data sources and create external tables.
Amazon AWS Glue Data Catalog is a centralized metadata management service that helps data professionals discover data and supports data governance in AWS cloud. An Autonomous AI Database instance has the ability to synchronize automatically data catalog metadata with AWS Glue Data Catalog allowing database users to immediately use Autonomous AI Database to query data stored in the AWS cloud.
Synchronizing with AWS Glue Data Catalog has the same properties as synchronizing with OCI Data Catalog. Synchronization is dynamic, keeping the database up-do-date with respect to changes to the underlying data, reducing administration cost as it automatically maintains hundreds to thousands of tables.
Concepts Related to Querying with AWS Glue Data Catalog
An understanding of the following concepts is necessary for querying with Amazon Web Service (AWS) Glue data catalogs.
AWS Glue Data Catalog: Database
An AWS Glue database represents a collection of relational table definitions, organized in a logical group. Each AWS Glue data catalog instance manages multiple databases.
AWS Glue Data Catalog: Table
An AWS Glue table represents a relational table over data stored in the AWS cloud. An AWS Glue table defines the schema of the underlying data and consists of column information, partition information, serialization information, storage information, statistics, user-defined metadata and other metadata. Tables in AWS Glue data catalog can be created manually, or automatically using an AWS Glue crawler.
Glue Data Catalog: Crawler
You can use a crawler to populate the AWS Glue data catalog with tables. This is the primary method used by most AWS Glue users. A crawler can crawl multiple data stores in a single run. Upon completion, the crawler creates or updates one or more tables in your data catalog. Extract, transform, and load (ETL) jobs that you define in AWS Glue use these data catalog tables as sources and targets. The ETL job reads from and writes to the data stores that are specified in the source and target data catalog tables.
AWS Glue tables can be created manually by the user or automatically using a predefined or a custom crawler. Crawlers connect to the underlying data stores (for example, Amazon S3), invoke classifiers for deriving the schema of the data, and create AWS Glue tables for storing the inferred metadata. AWS Glue provides classifiers for common file types, such as CSV, JSON, Parquet, and AVRO.
Mapping Between Autonomous AI Database and AWS Glue
During the synchronization process, external tables are created in Autonomous AI Database derived from the AWS Glue Data Catalog databases and tables over Amazon S3.
AWS Glue organizes collected metadata in databases and tables. An AWS Glue database is a collection of relational table definitions. AWS Glue tables that describe the common schema and properties of the files associated with the table.
AWS Glue follows the relational model for representing attributes. For mapping hierarchical schemas to relational schemas, AWS Glue infers the schema of the semi-structured data and flattens the data to a relational schema using an ETL process.
The following table represents the mapping between OCI Data Catalog concepts and AWS Glue Data Catalog Concepts.
| OCI Data Catalog | AWS Glue Data Catalog | Oracle AI Database |
|---|---|---|
| Data Asset | Database | Schema |
| Folder | (Bucket) | Schema |
| Logical Entity | Table | Table |
User Workflow for Querying with AWS Glue Data Catalog
The basic user workflow for querying AWS S3 data with AWS Glue Data Catalog involves connecting to AWS Glue Data Catalog, synchronizing with Autonomous AI Database to automatically create external tables, and then querying the S3 data.
The Database Data Catalog Administrator creates a connection between the Autonomous AI Database instance and an AWS Glue Data Catalog instance, then configures and runs a synchronization (sync) between the AWS Glue Data Catalog and Autonomous AI Database. Autonomous AI Database automatically creates an external table for tables harvested by AWS Glue about data stored in S3.
The Database Data Catalog Query Admin or Database Admin grants READ access to the generated external tables so that Data Analysts and other database users can browse and query Autonomous AI Database without having to manually derive the schema for the external data sources and create external tables.
Users
The table below describes the different types of users that perform the user workflow actions.
| User | Description |
|---|---|
| Database Data Catalog Administrator | Database user with DCAT_SYNC role. |
| Database Data Catalog Query Administrator | Database user able to grant access on automatically created external tables to other users. |
| Data Analyst | Database user on Autonomous AI Database querying data in AWS S3 either by querying automatically created external tables or by interacting directly with AWS Glue Data Catalog. |
| AWS Glue Data Catalog User | AWS user with access to an AWS Glue Data Catalog. |
| AWS S3 Object Storage User | AWS user with access to data stored in AWS S3 |
User Workflow
The table below describes each action included in the workflow and what type of user can perform the action.
Note
Note: The DBMS_DCAT package is available for performing the tasks required to query AWS S3 object storage using AWS Glue Data Catalog. See DBMS_DCAT Package.
| Action | Who is the user | Description |
|---|---|---|
| Create policies | Database Data Catalog Administrator | The Autonomous AI Database user credential must have the appropriate permissions to access AWS Glue Data Catalog and to read from S3 object storage. More information: Required Credentials and IAM Policies. |
| Create credentials | Database Data Catalog Administrator | Ensure database credentials are in place to access AWS Glue Data Catalog and to query S3 object storage. The user calls `DBMS_CLOUD.CREATE_CREDENTIAL` to create user credentials. Note: Only Amazon Web Services (AWS) credentials are supported. AWS Amazon Resource Names (ARN) credentials are not supported. More information: [DBMS_CLOUD CREATE_CREDENTIAL Procedure](dbms-cloud-subprograms.html#GUID-742FC365-AA09-48A8-922C-1987795CF36A) |
| Connect | Database Data Catalog Administrator | Establish a connection between an Autonomous AI Database instance and an AWS Glue Data Catalog instance. The connection uses the privileges of the AWS Glue Data Catalog User. Connections from an Autonomous AI Database instance to multiple AWS Glue Data Catalog instances is supported. To initiate a connection between an Autonomous AI Database instance and an AWS Glue Data Catalog instance the user:
Once the connection has been made, Autonomous AI Database stores the associated metadata, such as the AWS Glue catalog id, region, endpoint, and credential objects. More information: SET_DATA_CATALOG_CONN Procedure, UNSET_DATA_CATALOG_CONN Procedure, SET_DATA_CATALOG_CREDENTIAL Procedure, SET_OBJECT_STORE_CREDENTIAL Procedure. |
| Synchronize | Database Data Catalog Administrator | The user can manually start a synchronization with connected AWS Glue Data Catalogs using Synchronization does the following:
|
| Monitor Synchronization | Database Data Catalog Administrator | The user can view the sync status by querying the USER_LOAD_OPERATIONS view. After the sync process has completed, the user can view a log of the sync results, including details about the mappings to external tables.More information: [Monitoring and Troubleshooting Loads](load-data-cloud-monitor.html#GUID-657A579F-CF44-458B-8C97-3E50D0C98006) |
| Grant privileges | Database Data Catalog Query Administrator, Database Administrator | The database Data Catalog Query Administrator or Database Administrator must grant READ privileges on generated external tables to data analyst users. This allows the data analysts to query the generated external tables. |
| Query | Data Analyst | Data analysts are able to review the synced schemas and tables in the GLUE$* schemas and query the external tables through any tool or application that supports Oracle SQL. Data in S3 is accessed using the privileges of the AWS S3 object storage user. More information: Example: Query with AWS Glue Data Catalog |
| Terminate connections | Database Data Catalog Administrator | To remove an existing Data Catalog association, the user calls the This action is only done when you no longer plan on using the connected AWS Glue Data Catalog and the external tables that are derived from the catalog. This action deletes AWS Glue Data Catalog metadata, and drops synced external tables from the Autonomous AI Database instance. More information: UNSET_DATA_CATALOG_CONN Procedure |
Example: Query with AWS Glue Data Catalog
This example steps you through the process of running queries over datasets stored in Amazon Simple Storage Service (Amazon S3) using an AWS Glue Data Catalog.
In this example, metadata in an AWS Glue Data Catalog is inspected to see what Amazon S3 objects have been previously crawled and exist in the data catalog. Autonomous AI Database is then associated with the AWS Glue Data Catalog and Amazon S3. The data catalog is synchronized with Autonomous AI Database to create external tables over the datasets stored in Amazon S3. The external tables are used to query the datasets in Amazon S3.
-
Inspect metadata in AWS Glue Data Catalog.
-
Launch the AWS Glue console.
-
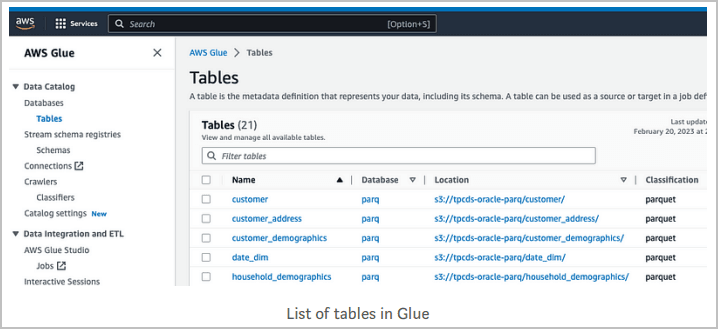
Navigate to the data catalog, databases and tables to find existing objects.
In this example, some objects exist in Amazon S3 that AWS Glue has previously crawled and created tables for as shown below:
-
-
Associate AWS Glue with Autonomous AI Database.
-
Create credentials in Autonomous AI Database.
The following procedure call includes the access ID and secret key to provide Autonomous AI Database with access to the underlying data in Amazon S3.
<pre class="copy"><code>exec dbms_cloud.create_credential('CRED_AWS','<access id>', '<access key>');</code></pre> -
Associate the credentials with the AWS Glue Data Catalog and Amazon S3 object storage.
These procedure calls associate the data catalog and object storage, respectively, with the credentials.
<pre class="copy"><code>exec dbms_dcat.set_data_catalog_credential('CRED_AWS'); exec dbms_dcat.set_object_store_credential('CRED_AWS');</code></pre> -
Set up an AWS region where Glue is running.
<pre class="copy"><code>exec dbms_dcat.set_data_catalog_conn(region => 'us-west-2', catalog_type=>'AWS_GLUE');</code></pre>
-
-
Synchronize metadata to create external tables in Autonomous AI Database derived from AWS Glue databases and tables.
-
Now that the association is done, use the
all_glue_databasesview to find what databases are inside an AWS Glue Data Catalog.<pre class="copy"><code>select * from all_glue_databases order by name;</code></pre> -
Use the
all_glue_tablesview to get a list of tables available for sync.<pre class="copy"><code>select * from all_glue_tables order by database_name, name;</code></pre>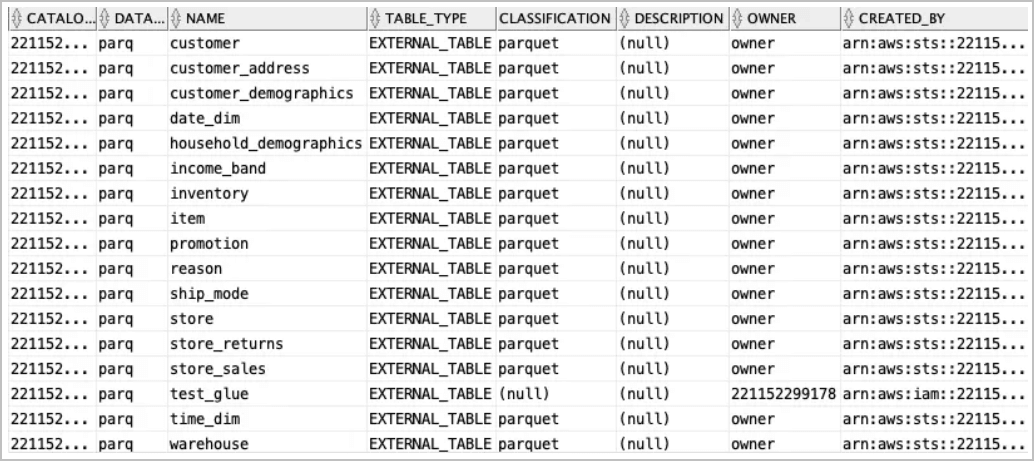
-
Synchronize Autonomous AI Database with two tables,
storeanditem, found in theparqdatabase.<pre class="copy"><code>begin dbms_dcat.run_sync( synced_objects => ' { "database_list": [ { "database": "parq", "table_list": ["store","item"] } ] }', error_semantics => 'STOP_ON_ERROR'); end; /</code></pre>
-
-
Inspect new objects in Autonomous AI Database and run a query on top of S3.
-
Use SQL Developer to view new objects created by the previous sync operation.
The
GLUE$PARQ_TPCDS_ORACLE_PARQschema was generated and named automatically by thedbms_dcat.run_syncprocedure call.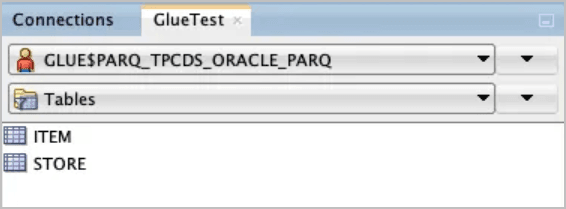
-
Run a SQL query over datasets stores in Amazon S3.
<pre class="copy"><code>SELECT * FROM glue$parq_tpcds_oracle_parq.store;</code></pre>
-