ビジョンとOracle Analytics Cloud (OAC)の統合
Vision SDKを使用してイメージ内のオブジェクトを検出し、その情報をデータ・ウェアハウスの表に投影するデータ統合フローを作成します。この出力データは、Oracle Analytics Cloudでビジュアライゼーションの作成やパターンの検索に使用されます。
これは、VisionとOAC間のシステムの高レベルのフローです。 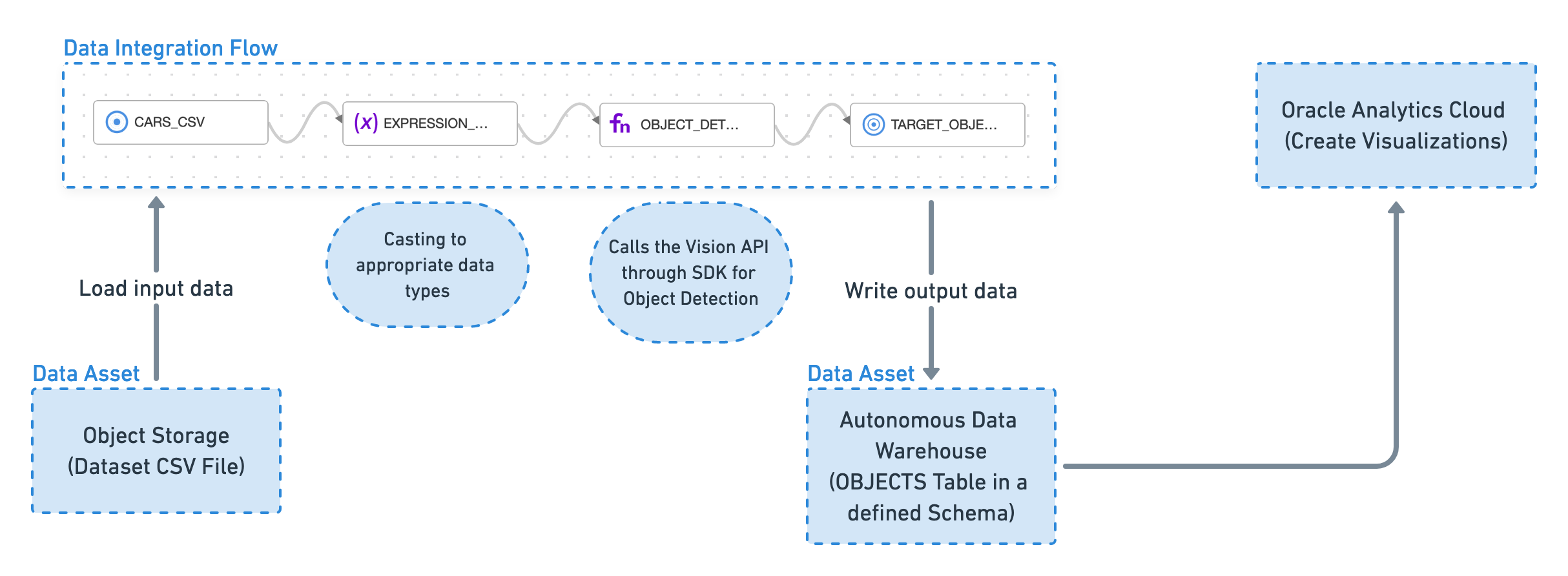
開始前
このチュートリアルに従うには、VCNネットワーク、関数およびAPIゲートウェイを作成し、データ統合およびVisionを使用できる必要があります。
必要なポリシーについて管理者に相談してください。
必要なポリシーの設定
必要なポリシーを設定するには、次のステップに従います。
1.Virtual Cloudネットワークの作成
チュートリアルの後半で作成したサーバーレス・ファンクションおよびAPIゲートウェイのホームとして機能するVCNを作成します。
1.1 インターネット・アクセスを使用したVCNの作成
インターネット・アクセスを持つVCNを作成するには、次のステップに従います。
- ナビゲーション・メニューで、「ネットワーキング」を選択します。
- 「Virtual Cloud Networks」を選択します。
- VCNウィザードの起動をスリックします。
- 「インターネット接続性を持つVCNの作成」を選択します。
- 「VCNウィザードの起動」を選択します。
- VCNの名前を入力します。機密情報を入力しないでください。
- 「次」を選択します。
- 「作成」を選択します。
1.2 インターネットからのVCNへのアクセス
ポート43でトラフィックを許可するには、パブリック・リージョン・サブネットに対して新しいステートフル・イングレス・ルールを追加する必要があります。
このタスクを試行する前に、1.1インターネット・アクセスによるVCNの作成を完了してください。
APIゲートウェイは、デフォルトでオープンされていないポート443で通信します。
2.APIゲートウェイの作成
APIゲートウェイを使用すると、作成したすべての関数を、ユーザーが使用できる単一のエンドポイントに集約できます。
3. エンリッチメント・ファンクションの作成
Oracle Cloud Infrastructure Data Integrationからコールできるエンリッチメント関数を作成するには、次のステップに従います。
オンデマンドでのみ実行されるサーバーレス関数を作成します。この関数は、データ統合で使用するために必要なスキーマに準拠しています。サーバーレス関数は、Python SDKを介してVisionのAPIを呼び出します。
3.1 アプリケーションの作成
3.2 ファンクションの作成
次のステップに従って、アプリケーションにファンクションを作成します。
このタスクを試行する前に、3.1アプリケーションの作成を完了してください。
最速の方法は、システムでPythonテンプレートを生成することです。
func.yamlの推奨コンテンツ。
schema_version: 20180708
name: object-detection
version: 0.0.1
runtime: python
build_image: fnproject/python:3.8-dev
run_image: fnproject/python:3.8
entrypoint: /python/bin/fdk /function/func.py handler
memory: 256
timeout: 300requirements.txtの推奨コンテンツ。
fdk>=0.1.40
oci
https://objectstorage.us-ashburn-1.oraclecloud.com/n/axhheqi2ofpb/b/vision-oac/o/vision_service_python_client-0.3.9-py2.py3-none-any.whl
pandas
requestsfunc.pyの推奨コンテンツ。
import io
import json
import logging
import pandas
import requests
import base64
from io import StringIO
from fdk import response
import oci
from vision_service_python_client.ai_service_vision_client import AIServiceVisionClient
from vision_service_python_client.models.analyze_image_details import AnalyzeImageDetails
from vision_service_python_client.models.image_object_detection_feature import ImageObjectDetectionFeature
from vision_service_python_client.models.inline_image_details import InlineImageDetails
def handler(ctx, data: io.BytesIO=None):
signer = oci.auth.signers.get_resource_principals_signer()
resp = do(signer,data)
return response.Response(
ctx, response_data=resp,
headers={"Content-Type": "application/json"}
)
def vision(dip, txt):
encoded_string = base64.b64encode(requests.get(txt).content)
image_object_detection_feature = ImageObjectDetectionFeature()
image_object_detection_feature.max_results = 5
features = [image_object_detection_feature]
analyze_image_details = AnalyzeImageDetails()
inline_image_details = InlineImageDetails()
inline_image_details.data = encoded_string.decode('utf-8')
analyze_image_details.image = inline_image_details
analyze_image_details.features = features
try:
le = dip.analyze_image(analyze_image_details=analyze_image_details)
except Exception as e:
print(e)
return ""
if le.data.image_objects is not None:
return json.loads(le.data.image_objects.__repr__())
return ""
def do(signer, data):
dip = AIServiceVisionClient(config={}, signer=signer)
body = json.loads(data.getvalue())
input_parameters = body.get("parameters")
col = input_parameters.get("column")
input_data = base64.b64decode(body.get("data")).decode()
df = pandas.read_json(StringIO(input_data), lines=True)
df['enr'] = df.apply(lambda row : vision(dip,row[col]), axis = 1)
#Explode the array of aspects into row per entity
dfe = df.explode('enr',True)
#Add a column for each property we want to return from imageObjects struct
ret=pandas.concat([dfe,pandas.DataFrame((d for idx, d in dfe['enr'].iteritems()))], axis=1)
#Drop array of aspects column
ret = ret.drop(['enr'],axis=1)
#Drop the input text column we don't need to return that (there may be other columns there)
ret = ret.drop([col],axis=1)
if 'name' not in ret.columns:
return pandas.DataFrame(columns=['id','name','confidence','x0','y0','x1','y1','x2','y2','x3','y3']).to_json(orient='records')
for i in range(4):
ret['x' + str(i)] = ret.apply(lambda row: row['bounding_polygon']['normalized_vertices'][i]['x'], axis=1)
ret['y' + str(i)] = ret.apply(lambda row: row['bounding_polygon']['normalized_vertices'][i]['y'], axis=1)
ret = ret.drop(['bounding_polygon'],axis=1)
rstr=ret.to_json(orient='records')
return rstr3.3 ファンクションのデプロイ
3.4 ファンクションの起動
関数をコールしてテストします。
このタスクを試行する前に、3.3ファンクションのデプロイを完了してください。
{"data":"eyJpZCI6MSwiaW5wdXRUZXh0IjoiaHR0cHM6Ly9pbWFnZS5jbmJjZm0uY29tL2FwaS92MS9pbWFnZS8xMDYxOTYxNzktMTU3MTc2MjczNzc5MnJ0czJycmRlLmpwZyJ9", "parameters":{"column":"inputText"}}{"id":1,"inputText":"https://<server-name>/api/v1/image/106196179-1571762737792rts2rrde.jpg"}echo '{"data":"<data-payload>", "parameters":{"column":"inputText"}}' | fn invoke <application-name> object-detection[{"id":1,"confidence":0.98330873,"name":"Traffic Light","x0":0.0115499255,"y0":0.4916201117,"x1":0.1609538003,"y1":0.4916201117,"x2":0.1609538003,"y2":0.9927374302,"x3":0.0115499255,"y3":0.9927374302},{"id":1,"confidence":0.96953976,"name":"Traffic Light","x0":0.8684798808,"y0":0.1452513966,"x1":1.0,"y1":0.1452513966,"x2":1.0,"y2":0.694972067,"x3":0.8684798808,"y3":0.694972067},{"id":1,"confidence":0.90388376,"name":"Traffic sign","x0":0.4862146051,"y0":0.4122905028,"x1":0.8815201192,"y1":0.4122905028,"x2":0.8815201192,"y2":0.7731843575,"x3":0.4862146051,"y3":0.7731843575},{"id":1,"confidence":0.8278353,"name":"Traffic sign","x0":0.2436661699,"y0":0.5206703911,"x1":0.4225037258,"y1":0.5206703911,"x2":0.4225037258,"y2":0.9184357542,"x3":0.2436661699,"y3":0.9184357542},{"id":1,"confidence":0.73488903,"name":"Window","x0":0.8431445604,"y0":0.730726257,"x1":0.9992548435,"y1":0.730726257,"x2":0.9992548435,"y2":0.9893854749,"x3":0.8431445604,"y3":0.9893854749}]4. ファンクション・ポリシーの追加
5. Oracle Cloud Infrastructureデータ統合ワークスペースの作成
データ統合を使用する前に、その機能を使用する権限があることを確認してください。
データ統合を使用できるようにするポリシーを作成します。
6. データ統合ポリシーの追加
データ統合を使用できるようにポリシーを更新します。
5を完了します。このタスクを試行する前に、Oracle Cloud Infrastructure Data Integration Workspaceを作成します。
7. データ・ソースおよびシンクの準備
駐車場イメージと、イメージがサンプル・データとして取得された日付を使用しています。
データ統合およびVisionを使用してオブジェクト検出分析を実行するデータ・ソースとして、パーク状態の自動車のイメージ(またはそれ以上)を10個収集します。
7.1 サンプル・データのロード
駐車した車のイメージのサンプル・データをバケットにロードします。
-
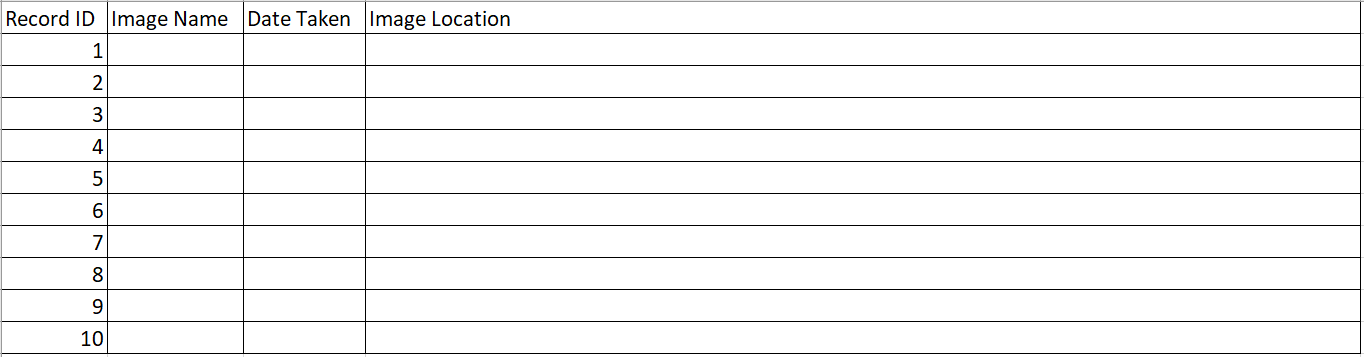
4つの列と10行の表を含むCSVファイルを作成します。列名は、「レコードID」、「イメージ名」、「取得日」および「イメージの場所」です。[レコードID]カラムに1から10を入力します。
サンプル・データ・ファイル
-
イメージ名、取得日およびイメージの場所を指定して、表に入力します。
イメージの場所を確認するには、バケットを表示するときにコンソールでイメージの「アクション」メニュー(
 )を選択します。「ビュー・オブジェクトの詳細」を選択し、URLパスをcars.csvにコピーします。
)を選択します。「ビュー・オブジェクトの詳細」を選択し、URLパスをcars.csvにコピーします。
7.2 ステージング・バケットの作成
データ統合では、データをデータ・ウェアハウスに公開する前に、中間ファイルをダンプするステージングの場所が必要です。
このタスクを実行する前に、7.1サンプル・データのロードを完了します。
- コンソールのナビゲーション・メニューで、「ストレージ」を選択します。
- 「バケット」を選択します。
- 「Create Bucket」を選択します。
-
適切な名前(
data-stagingなど)を指定します。機密情報を入力しないでください。 - 「作成」を選択します。
- すべてのデフォルト値を受け入れます。
7.3 ターゲット・データベースの準備
7.4 分析データを投影する表の作成
8. データ統合でのデータ・フローの使用
データ統合でデータ・フローを作成するために必要なコンポーネントを作成します。
データ・フローは次のとおりです。 
基礎となるすべてのストレージリソースは、前の章で作成しました。データ統合では、データ・フローの各要素のデータ・アセットを作成します。
8.1 ソースおよびステージングのデータ・アセットの作成
8.2 ターゲットのデータ・アセットの作成
8.3 データ・フローの作成
データ統合でデータ・フローを作成して、ファイルからデータを収集します。
このタスクを試行する前に、8.2ターゲットのデータ・アセットの作成を完了してください。
- Vision-labプロジェクトの詳細ページで、「データ・フロー」を選択します。
- 「データ・フローの作成」を選択します。
- データ・フロー・デザイナで、「プロパティ」パネルを選択します。
-
「名前」に、
lab-data-flowと入力します。 - 「作成」を選択します。
8.4 データ・ソースの追加
次に、データ・ソースをデータ・フローに追加します。
このタスクを試行する前に、8.3データ・フローの作成を完了してください。
8.3データ・フローの作成でデータ・フローを作成した後も、デザイナが開いたままになり、次のステップを使用してデータ・ソースを追加できます。
8.5 式の追加
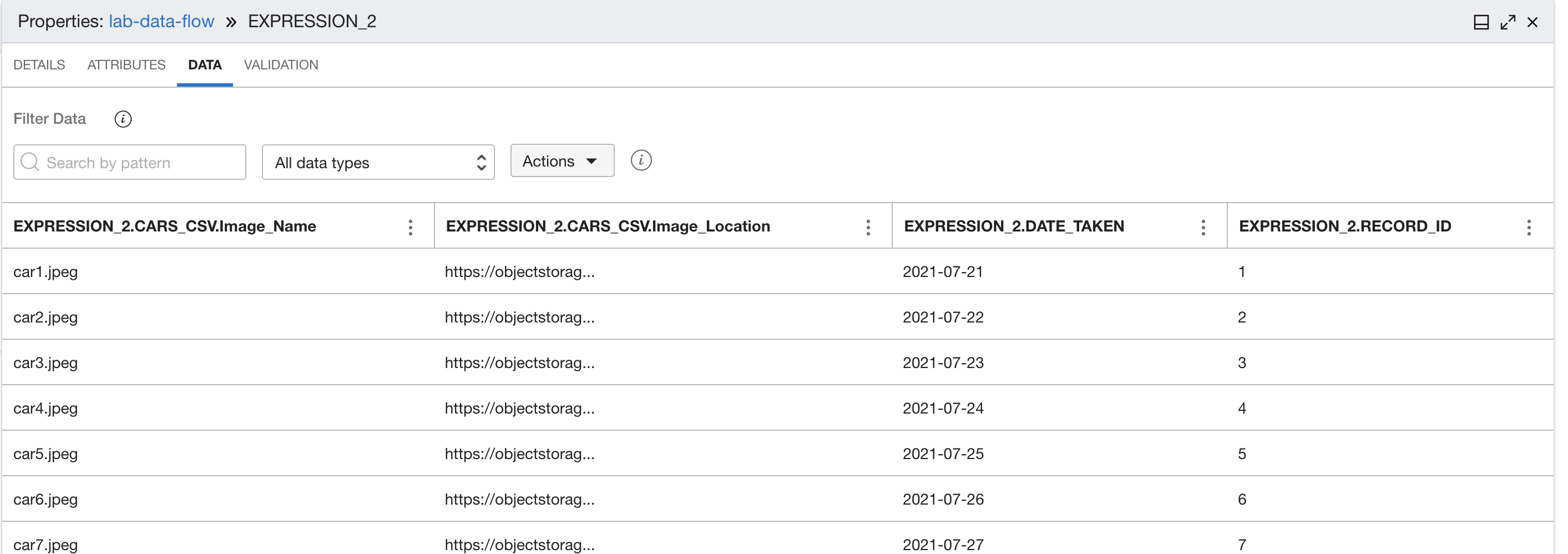
式を追加して、IDの形式を整数に、date_takenフィールドの形式を日付に変更します。
このタスクを試行する前に、8.4データ・ソースの追加を完了してください。
-
新しいフィールドを表示するには、式の「データ」タブを選択します。
データ・フィールド
8.6 関数の追加
8.7 データ・ウェアハウス表への出力のマッピング
センチメント分析の出力をデータ・ウェアハウス表にマップします。
このタスクを試行する前に、8.6ファンクションの追加を完了してください。
-
ファンクションの出力をターゲット・データベース表の正しいフィールドにマップします。次の表のマッピングを使用します。
関数出力マップ 名前 マッピング RECORD_ID RECORD_ID IMAGE_NAME Image_Name DATE_TAKEN DATE_TAKEN IMAGE_LOCATION Image_Location OBJECT_NAME 名前 OBJECT_CONFIDENCE 自信 頂点 X1 x0 頂点 Y1 y0 頂点 X2 x1 頂点 Y2 y1 頂点 X3 x2 頂点 Y3 y2 頂点 X4 x3 頂点 Y4 y3 マッピングは次のようになります。 マッピング1から4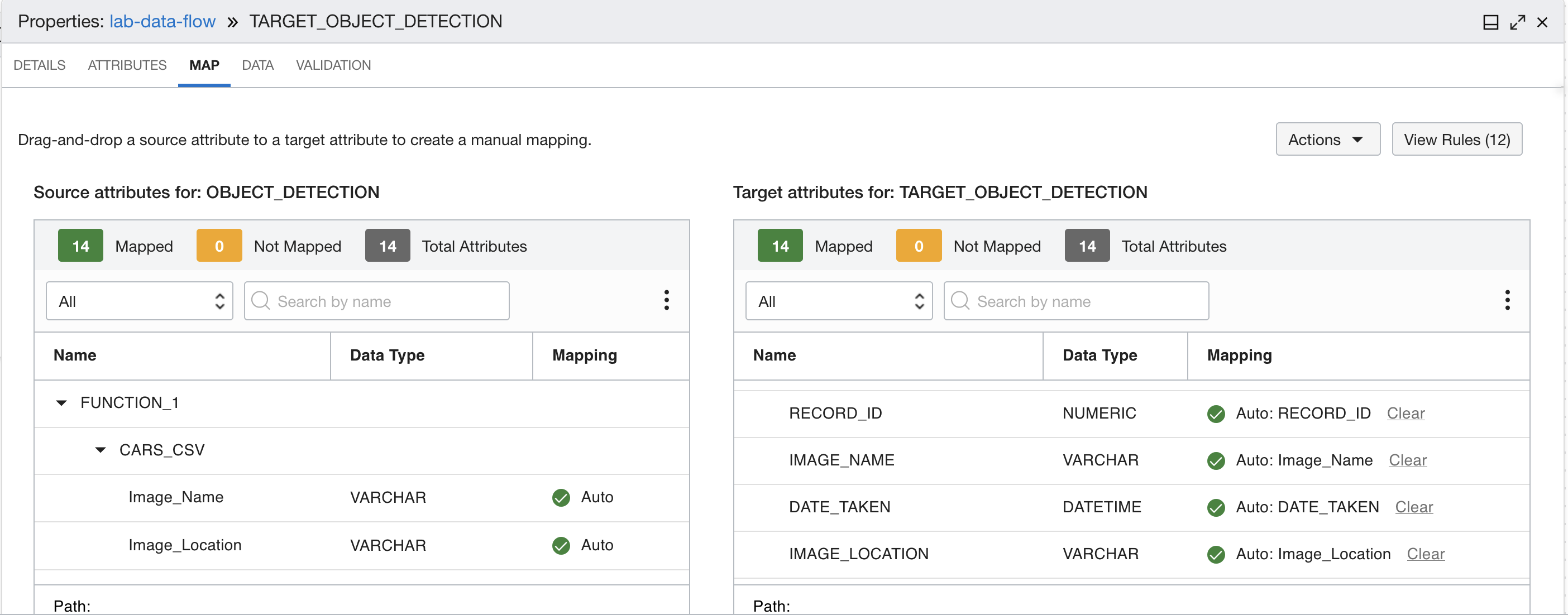 5から8へのマッピング
5から8へのマッピング 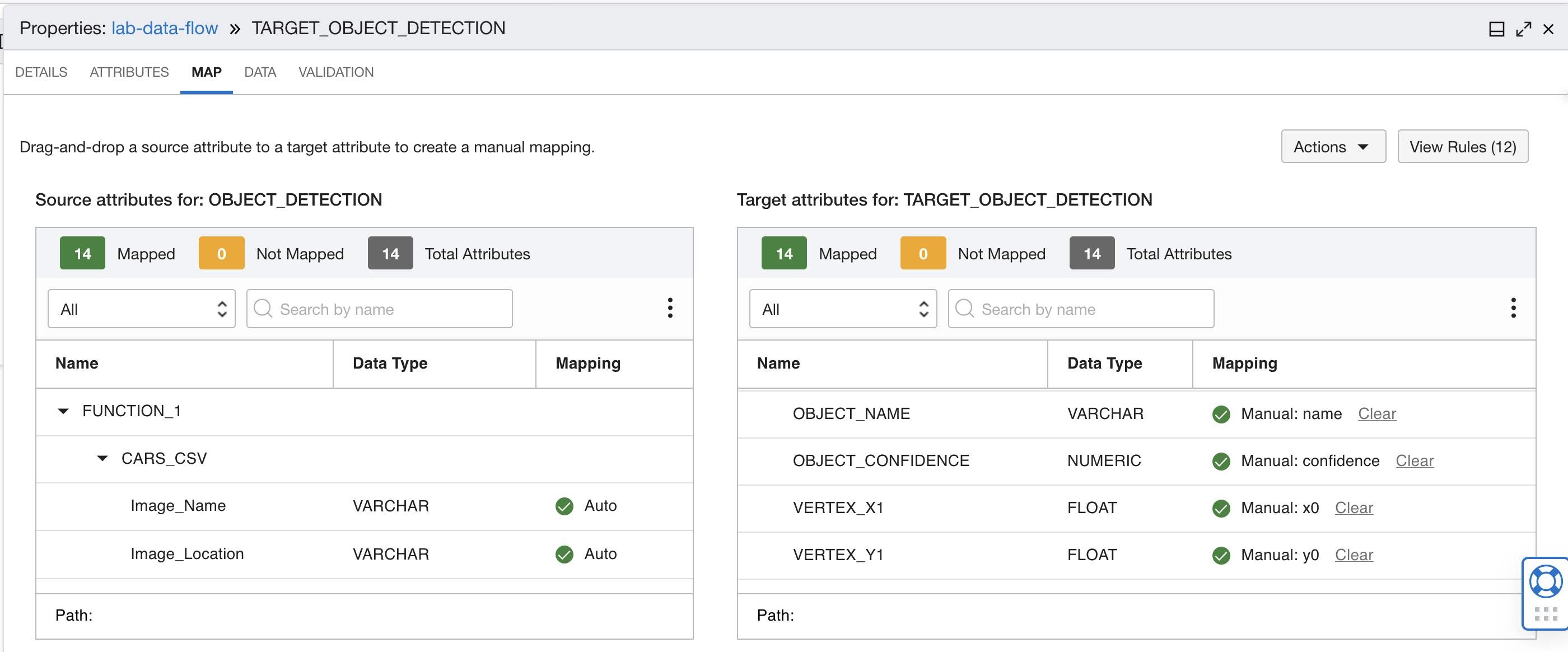 9から12へのマッピング
9から12へのマッピング 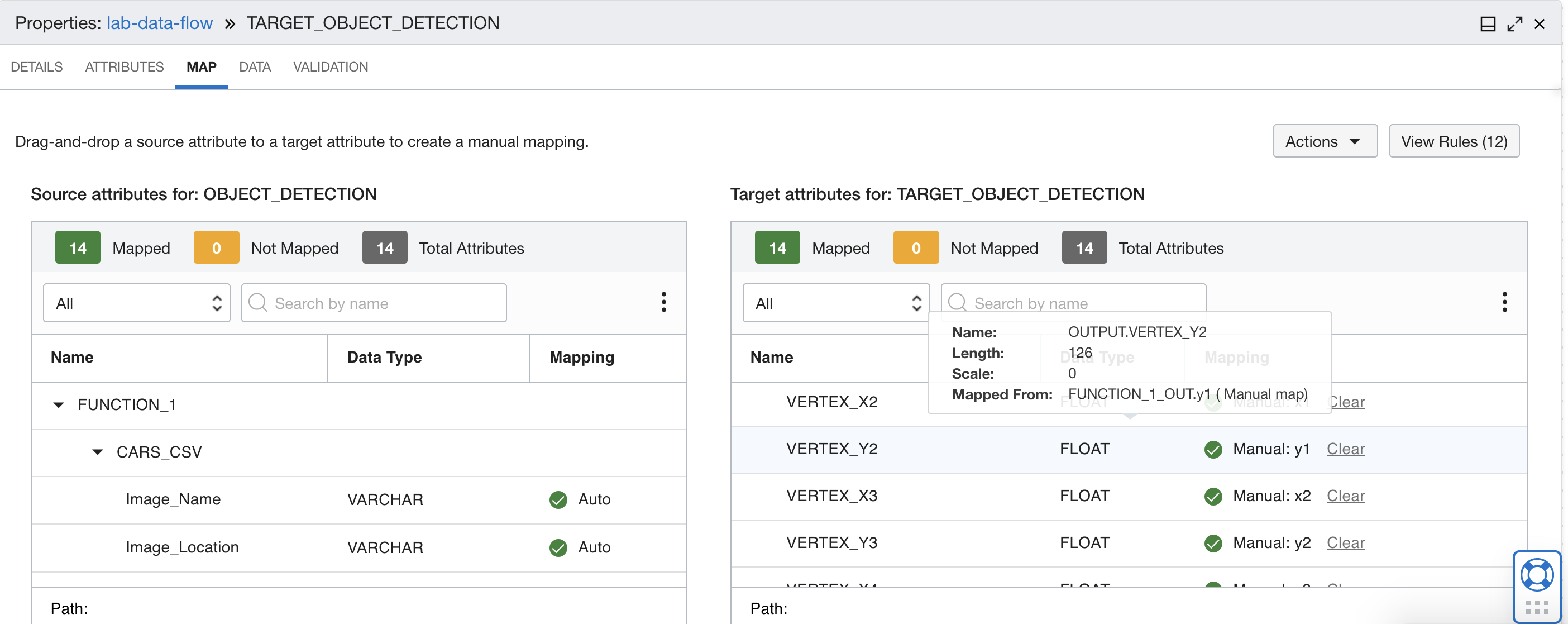 マッピング13および14
マッピング13および14 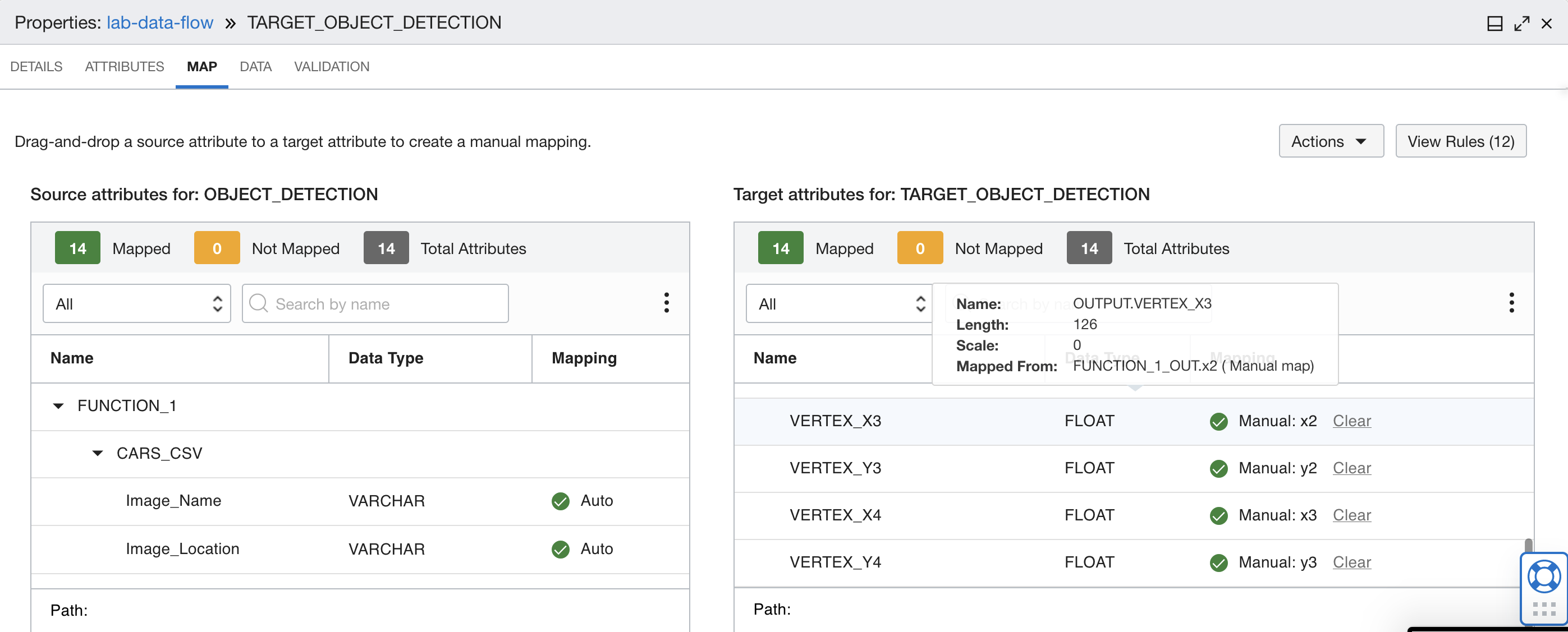
8.8 データ・フローの実行
データ・フローを実行してターゲット・データベースに移入します。
このタスクを実行する前に、8.7データ・ウェアハウス表への出力のマッピングを完了します。
-
ワークスペースの「クイック・アクション」メニュー()で、「統合タスクの作成」を選択します。
作成プロセスの一環として、8.3データ・フローの作成で作成したプロジェクトおよびデータ・フローを選択します。
9. Analytics Cloudのデータの視覚化
Analytics Cloudを使用して作成したデータを表示します。
Analytics Cloudにアクセスし、Analytics Cloudインスタンスを作成する必要があります。
9.1 Analytics Cloudインスタンスの作成
Analytics Cloudインスタンスを作成するには、次のステップに従います。
Complete 8. Use a Data Flow in Data Integration before trying this task.
- コンソールのナビゲーション・メニューから、「分析とAI」を選択します。
- 「Analytics Cloud」を選択します。
- 「コンパートメント」を選択します。
- インスタンスの作成を選択します。
- 「名前」を入力します機密情報を入力しない
-
2 OCPUsを選択します。他の構成パラメータはデフォルト値として保持されます。 - 「作成」を選択します。
9.2 データ・ウェアハウスへの接続の作成
Analytics Cloudインスタンスからデータ・ウェアハウスへの接続を設定するには、次のステップに従います。
このタスクを試行する前に、9.1 Analytics Cloudインスタンスの作成を完了してください。
9.3 データセットの作成
データセットを作成するには、次のステップに従います。
このタスクを試行する前に、9.2データ・ウェアハウスへの接続の作成を完了してください。
- 「データ」を選択します
- 「作成」を選択します。
- 「新規データセットの作成」を選択します。
- データ・ウェアハウスを選択します。
- USER1データベースから、OBJECTS表をキャンバスにドラッグします。
- データセットを保存します。
9.4 ビジュアライゼーションの作成
Analytics Cloudにデータを表示するには、次のステップに従います。
このタスクを試行する前に、9.3データセットの作成を完了してください。
-
「色」で、OBJECT_NAMEを選択します。
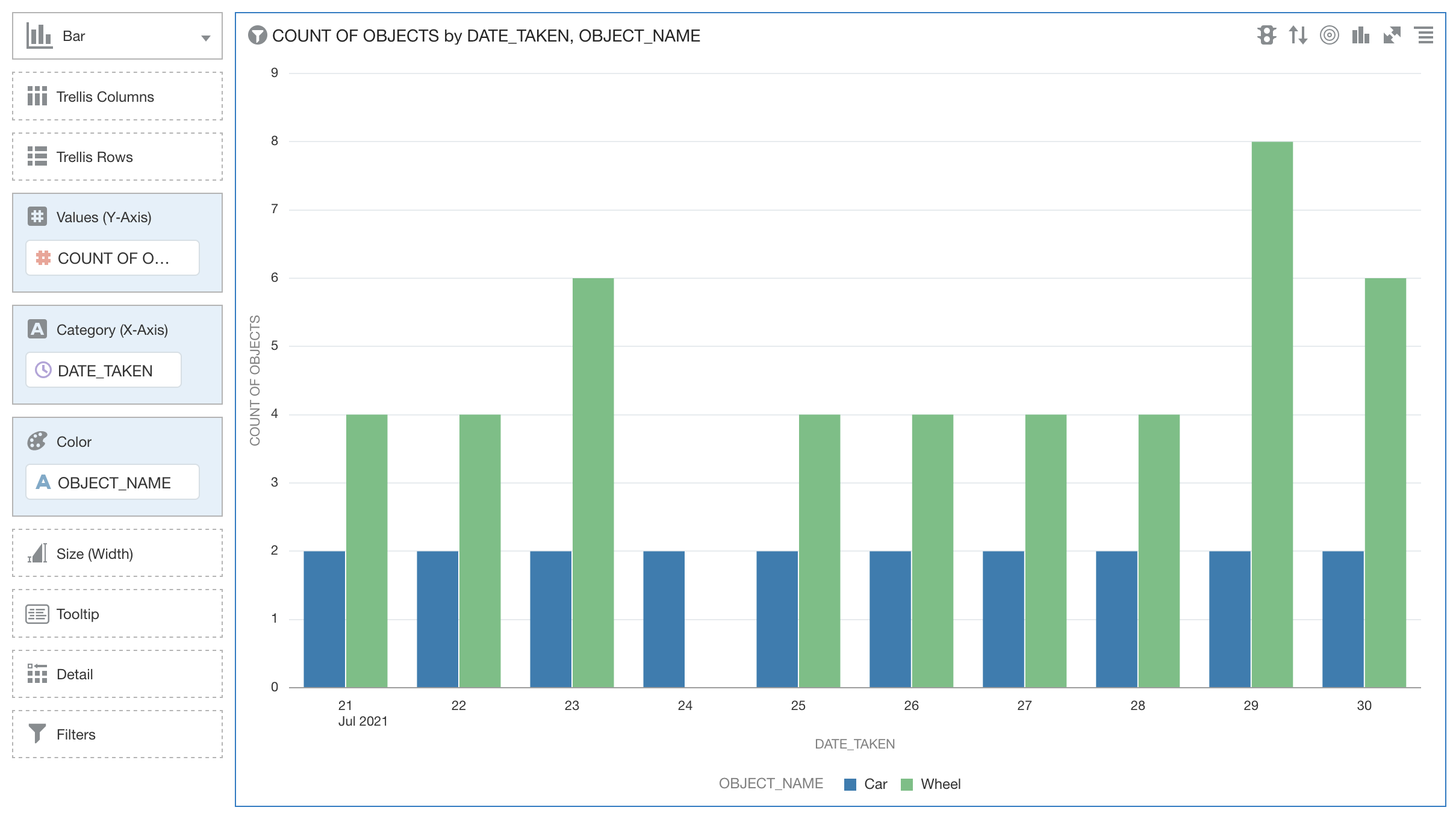
次のようなグラフが表示されます。