事前訓練された文書AIモデル
Visionは、ビジネス文書からテキストおよび構造を編成および抽出できる事前トレーニング済文書AIモデルを提供します。
VisionのAnalyzeDocumentおよびDocumentJob機能は、ドキュメント理解という新しいサービスに移行しています。次の機能は影響を受けます:
- 表の検出
- ドキュメント分類
- 入金キー/値抽出
- ドキュメントOCR
使用例
事前トレーニング済ドキュメントAIモデルを使用すると、バックオフィス業務を自動化し、領収書をより正確に処理できます。
- インテリジェント検索
- ドキュメント・タイプやキー・フィールドなどのメタデータでイメージ・ベースのファイルをエンリッチして、取得を容易にします。
- 費用レポート
- 入金から必要な情報を抽出して、ビジネス・ワークフローを自動化します。たとえば、従業員経費レポート、支出コンプライアンス、払戻などです。
- ダウンストリーム自然言語処理(NLP)
- PDFファイルからテキストを抽出し、表または単語と行でNLPの入力として整理します。
- ロイヤルティ・ポイントの獲得
- アイテム数または合計支払金額に基づいて、受領書からのロイヤルティ・ポイント計算を自動化します。
サポートされている形式
Visionは複数の文書形式をサポートしています。
- JPEG
- PNG
- TIFF
事前トレーニング済モデル
Visionには5つのタイプの事前トレーニング済モデルがあります。
光学式文字認識(OCR)
Visionは文書内のテキストを検出して認識できます。言語分類はドキュメントの言語を識別し、OCRはイメージ内で検出された印刷テキストまたは手書きテキストの周囲に境界ボックスを描画し、テキストをデジタル化します。
テキストを含むPDFがある場合、Visionはその文書内のテキストを検索し、テキストを抽出します。次に、識別されたテキストの境界ボックスを提供します。テキスト検出は、ドキュメントAIまたはイメージ分析モデルで使用できます。
Visionは、各テキスト・グループに対して信頼度スコアを提供します。信頼度スコアは10進数です。スコアが1に近いと、抽出されたテキストの信頼性が高いことを示しますが、スコアが小さいと信頼度スコアが低くなります。各ラベルの信頼度スコアの範囲は0から1です。
OCRのサポートは英語に制限されています。イメージ内のテキストが英語であることがわかっている場合は、言語を
Engに設定します。- 単語抽出
- テキスト行の抽出
- 信頼性スコア
- 境界ポリゴン
- 単一のリクエスト
- バッチ・リクエスト
- 言語分類は複数の言語を識別しますが、OCRは英語に制限されます。
VisionでのOCRの使用例。
- 入力ドキュメント
図1. OCR入力 
.{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "TEXT_DETECTION" }, { "featureType": "LANGUAGE_CLASSIFICATION", "maxResults": 5 } ] } }- 出力:
図2. OCR出力 
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 }, { "languageCode": "ARA", "confidence": 4.7619238e-7 }, { "languageCode": "NLD", "confidence": 7.2325456e-8 }, { "languageCode": "CHI_SIM", "confidence": 3.0645523e-8 }, { "languageCode": "ITA", "confidence": 8.6900076e-10 } ], "words": [ { "text": "Example", "confidence": 0.99908227, "boundingPolygon": { "normalizedVertices": [ { "x": 0.0664819944598338, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.035 }, { "x": 0.0664819944598338, "y": 0.035 } ] } ... "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 } ], ...
ドキュメント分類
文書分類を使用して、文書を分類できます。
- 請求書
- 受入
- 採用情報
- 税金フォーム
- ライセンス
- パスポート
- 銀行取引明細書
- チェック
- 給与明細
- その他
- ドキュメントを分類
- 信頼性スコア
- 単一のリクエスト
- バッチ・リクエスト
Visionでの文書分類の使用例。
- 入力ドキュメント
図3. ドキュメント分類入力
{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "DOCUMENT_CLASSIFICATION", "maxResults": 5 } ] } }- 出力:
- APIレスポンス:
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 }, { "documentType": "TAX_FORM", "confidence": 6.465067e-9 }, { "documentType": "CHECK", "confidence": 6.031838e-9 }, { "documentType": "BANK_STATEMENT", "confidence": 5.413888e-9 }, { "documentType": "PASSPORT", "confidence": 1.5554872e-9 } ], ... detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 } ], ...
表抽出
表抽出を使用して、ドキュメント内の表を識別し、その内容を抽出できます。たとえば、PDF領収書に税金と合計金額を含む表が含まれている場合、Visionはその表を識別して表構造を抽出します。
Visionでは、表の行数と列数、および各表のセルの内容が提供されます。各セルには信頼度スコアがあります。信頼度スコアは10進数です。スコアが1に近いと、抽出されたテキストの信頼性が高いことを示しますが、スコアが小さいと信頼度スコアが低くなります。各ラベルの信頼度スコアの範囲は0から1です。
- 罫線ありおよび罫線なしの表の抽出
- 境界ポリゴン
- 信頼性スコア
- 単一のリクエスト
- バッチ・リクエスト
- 英語のみ
Visionでの表抽出の使用例。
- 入力ドキュメント
図4. 表抽出入力 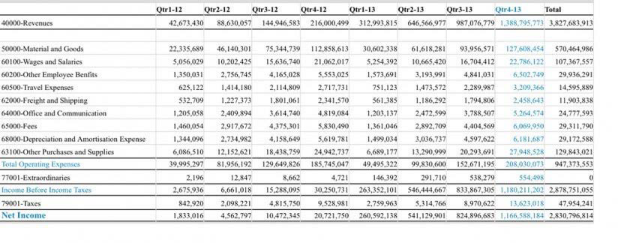
{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "TABLE_DETECTION" } ] } }- 出力:
図5. 表抽出出力 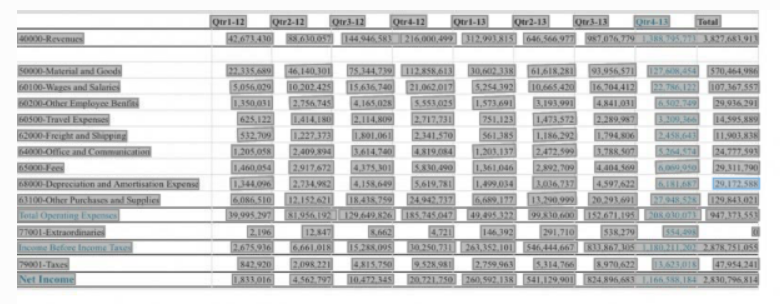
{ "documentMetadata": { "pageCount": 1, "mimeType": "application/pdf" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 2575, "height": 1013, "unit": "PIXEL" }, ... "tables": [ { "rowCount": 15, "columnCount": 9, "bodyRows": [ { "cells": [ { "text": "Qtr1-12", "rowIndex": 0, "columnIndex": 1, "confidence": 0.92011595, "boundingPolygon": { "normalizedVertices": [ { "x": 0.2532038834951456, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.05330700888450148 }, { "x": 0.2532038834951456, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 0 ] }, { "text": "Qtr2-12", "rowIndex": 0, "columnIndex": 2, "confidence": 0.919653, "boundingPolygon": { "normalizedVertices": [ { "x": 0.33048543689320387, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.05330700888450148 }, { "x": 0.33048543689320387, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 1 ] }, ...
キー値抽出(領収書)
キー値抽出を使用して、入金の事前定義済キーの値を識別できます。たとえば、入金に業者名、業者住所または業者電話番号が含まれている場合、Visionはこれらの値を識別してキー値ペアとして返すことができます。
- 事前定義済キー値ペアの値の抽出
- 境界ポリゴン
- 単一のリクエスト
- バッチ・リクエスト
- 領収書を英語のみでサポートします。
- MerchantName
- 領収書を発行しているマーチャントの名前。
- MerchantPhoneNumber
- 業者の電話番号。
- MerchantAddress
- 業者の住所。
- TransactionDate
- 入金が発行された日付。
- TransactionTime
- 入金が発行された時間。
- 合計
- すべての手数料および税金が消し込まれた後の入金の合計金額。
- 小計
- 税引前小計。
- Tax
- 売上税。
- ヒント
- 購入者が与えたチップの金額。
- ItemName
- アイテムの名前です。
- ItemPrice
- 品目の単価です。
- ItemQuantity
- 購入した各アイテムの数。
- ItemTotalPrice
- 明細品目の合計価格。
Visionでのキー値抽出の使用例。
- 入力ドキュメント
図6. キー・バリュー抽出(領収書)入力
{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "KEY_VALUE_DETECTION" } ] } }- 出力:
図7. キー値抽出(受信)出力 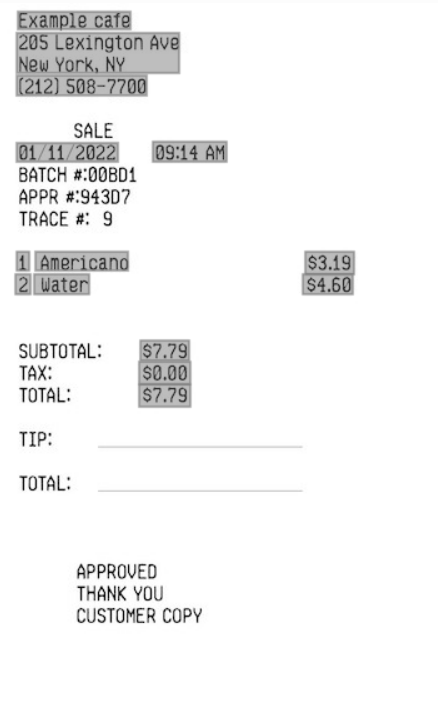
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, ... "documentFields": [ { "fieldType": "KEY_VALUE", "fieldLabel": { "name": "MerchantName" }, "fieldValue": { "valueType": "STRING", "boundingPolygon": { "normalizedVertices": [ { "x": 0.0664819944598338, "y": 0.011666666666666667 }, { "x": 0.3157894736842105, "y": 0.011666666666666667 }, { "x": 0.3157894736842105, "y": 0.035 }, { "x": 0.0664819944598338, "y": 0.035 } ] }, "wordIndexes": [ 0, 1 ], "value": "Example cafe" } }, ...
OCR(Optical Character Recognition) PDF
OCR PDFは、検索可能なPDFファイルをオブジェクト・ストレージに生成します。たとえば、Visionでは、テキストとイメージを含むPDFファイルを取得し、PDFでテキストを検索できるPDFファイルを返すことができます。
- 検索可能PDFの生成
- 単一のリクエスト
- バッチ・リクエスト
VisionでのOCR PDFの使用例。
- 入力
図8。 OCR ODF入力 
{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "source": "INLINE", "data": "......" }, "features": [ { "featureType": "TEXT_DETECTION", "generateSearchablePdf": true } ] } }- 出力:
- 検索可能PDF
事前トレーニングされた文書AIモデルの使用
Visionは、データ・サイエンティストを必要とせずにドキュメントに関するインサイトを抽出するための事前トレーニング済モデルを顧客に提供します。
事前トレーニング済モデルを使用する前に、次のものが必要です。
-
Oracle Cloud Infrastructureの有料テナンシ・アカウント。
-
Oracle Cloud Infrastructure Object Storageについて理解します。
Rest API、SDKまたはCLIを使用して、事前トレーニング済ドキュメントAIモデルをバッチ・リクエストとしてコールできます。コンソール、Rest API、SDKまたはCLIを使用して、事前トレーニング済ドキュメントAIモデルを単一のリクエストとしてコールできます。
バッチ・リクエストで許可される内容の詳細は、「制限」の項を参照してください。