Oracle Cloud Infrastructureデータ・フローの開始
このチュートリアルでは、任意のApache Sparkアプリケーションを任意のスケールで実行できるサービスであり、デプロイまたは管理するインフラストラクチャがないOracle Cloud Infrastructure Data Flowを紹介します。
以前にSparkを使用したことがある場合は、このチュートリアルからさらに詳しく学習できますが、Sparkに関する事前の知識は必要ありません。すべてのSparkアプリケーションおよびデータが提供されています。このチュートリアルでは、データ・フローにより、Sparkアプリケーションの実行が容易、繰返し可能、セキュアで、エンタープライズ全体での共有が簡単になる方法を示します
- データ・フローアプリケーションでJavaを使用してETLを実行する方法。
- SQLアプリケーションでのSparkSQLの使用方法。
- 簡単な機械学習タスクを実行するためにPythonアプリケーションを作成して実行する方法。
このチュートリアルは、spark-submitをCLIから使用するか、spark-submitおよびJava SDKを使用して実行することもできます。
- サーバーレス。つまり、Sparkクラスタのプロビジョニング、パッチ適用、アップグレードまたはメンテナンスを行うエキスパートは必要ありません。つまり、Sparkコードに集中するだけです。
- 簡単な操作とチューニング。Spark UIへのアクセスは1回クリックするだけで、IAM認可ポリシーによって管理されます。ユーザーにジョブの実行速度が遅すぎるという不満がある場合、「実行」へのアクセス権を持つ任意のユーザーがSpark UIを開いて根本原因に移動できます。Spark履歴サーバーへのアクセスは、すでに実行されたジョブと同じように単純です。
- バッチ処理に最適。アプリケーションの出力は、REST APIによって自動的に取得され、使用可能になります。4時間のSpark SQLジョブを実行して、パイプライン管理システムに結果をロードする必要がありますか。データ・フロー,では、2つのREST APIコールのみです。
- 統合されたコントロール。データ・フローでは、すべてのSparkアプリケーション、誰がそれを実行しているか、およびその使用量の統合ビューが提供されます。どのアプリケーションが最も多くのデータを書き込んでいるか、およびそれを実行しているのは誰かを知る必要がありますか。「データ書込み」列でソートするだけです。ジョブの実行時間が長すぎますか。適切なIAM権限を持つユーザーは、ジョブを表示して停止できます。
開始する前に
このチュートリアルを正常に実行するには、テナンシの設定が完了し、データ・フローにアクセスできる必要があります。
- コンソールで、ナビゲーション・メニューをクリックして、使用可能なサービスのリストを表示します。
- 「分析とAI」を選択します。
- 「ビッグ・データ」で、「データ・フロー」を選択します。
- 「アプリケーション」を選択します。
1. Javaを使用したETL
データ・フローでJavaアプリケーションを作成する方法を学習する演習
ここでのステップは、コンソールUIを使用する場合のものです。この演習は、spark-submitをCLIから使用するか、spark-submitをJava SDKとともに使用して実行できます。
データ処理アプリケーションの最も一般的な最初のステップは、ソースからデータを取得し、レポート作成や他の分析形式に適したフォーマットに取り込むことです。データベースでは、フラット・ファイルをデータベースにロードし、索引を作成します。Sparkでの最初のステップは、データの消去、およびテキスト・フォーマットからParquetフォーマットへの変換です。Parquetは効率的な読取りをサポートする最適化されたバイナリ・フォーマットで、レポートおよび分析に最適です。この演習では、ソース・データを取り込み、Parquetに変換して、関連するいくつかのことを実行します。データセットはBerlin Airbnbデータ・データセットで、クリエイティブ・コモンズCC0 1.0ユニバーサル(CC0 1.0)の「パブリック・ドメイン専用」ライセンスに基づいてKaggle Webサイトからダウンロードされました。

データはCSVフォーマットで指定され、最初のステップではこのデータをParquetに変換し、ダウンストリーム処理のためにオブジェクト・ストアに格納します。oow-lab-2019-java-etl-1.0-SNAPSHOT.jarと呼ばれるSparkアプリケーションが提供され、この変換が行われます。目的は、このSparkアプリケーションを実行し、適切なパラメータを使用して実行するデータ・フロー・アプリケーションを作成することです。はじめるため、この演習では、ステップごとに必要なパラメータを説明します。後でパラメータを自分で指定する必要があるため、入力内容と理由を理解している必要があります。
コンソールから、またはコマンドラインからSpark-submitを使用して、あるいはSDKを使用して、データ・フローJavaアプリケーションを作成します。
コンソールからデータ・フローにJavaアプリケーションを作成します。
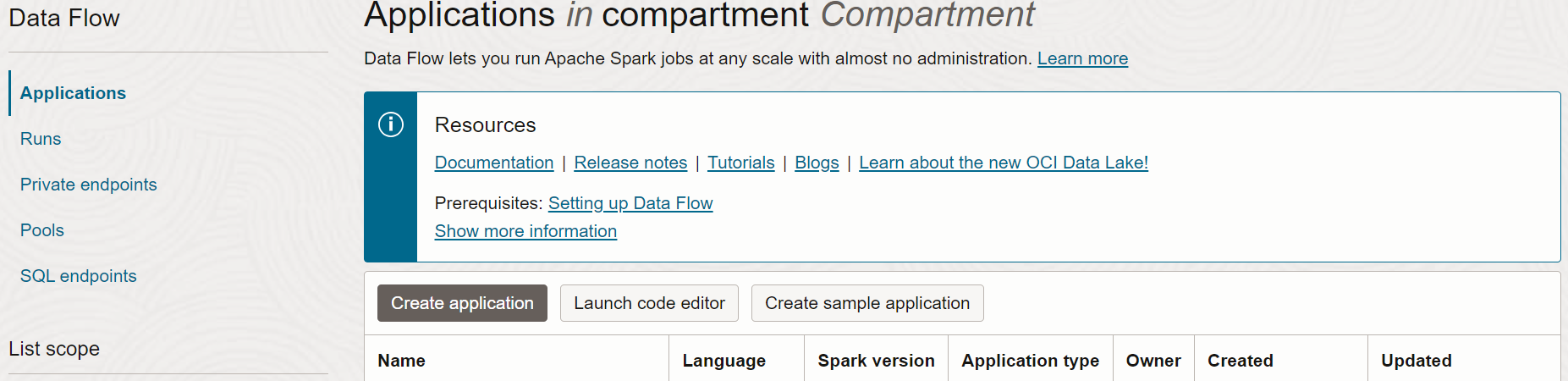
データ・フロー・アプリケーションの作成
- 左上にあるハンバーガ・メニューを展開して一番下までスクロールし、コンソールでデータ・フロー・サービスに移動します。
- 「データ・フロー」をハイライトしてから、「アプリケーション」を選択します。データ・フロー・アプリケーションを作成するコンパートメントを選択します。最後に、「アプリケーションの作成」をクリックします。
- 「Javaアプリケーション」を選択し、アプリケーションの名前(
Tutorial Example 1など)を入力します。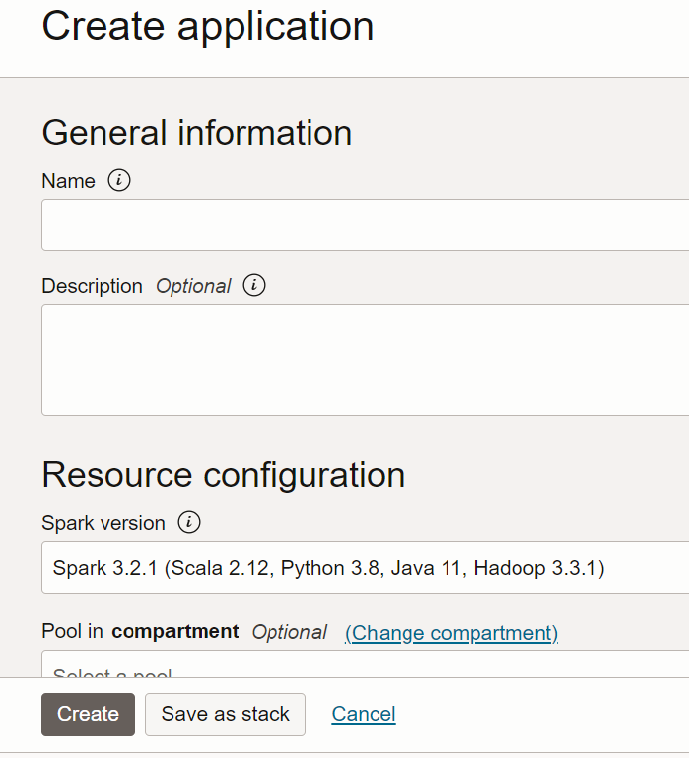
- 「リソース構成」に移動します。これらの値はすべてデフォルトのままにします。

- 「アプリケーション構成」までスクロールします。次のようにしてアプリケーションを構成します:
- ファイルURL: オブジェクト・ストレージ内のJARファイルの場所です。このアプリケーションの場所:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar - メイン・クラス名: Javaアプリケーションには、アプリケーションに依存するメイン・クラス名が必要です。この演習では次を入力します
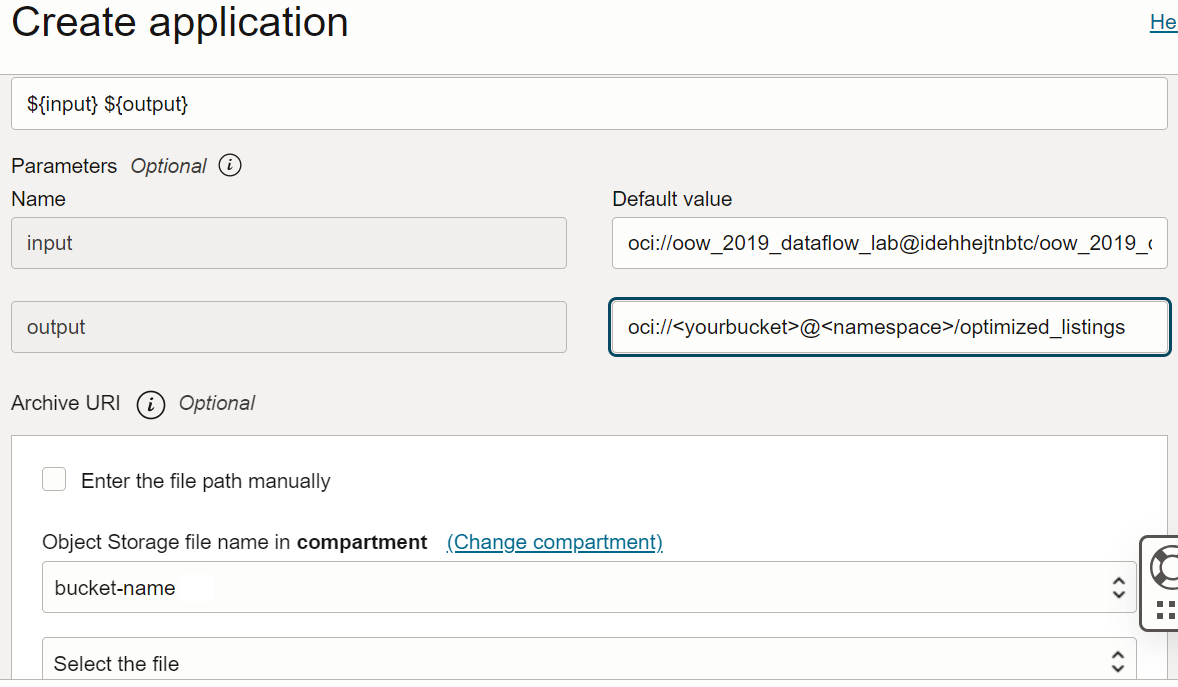
convert.Convert - 引数: Sparkアプリケーションでは、入力用と出力用の2つのコマンドライン・パラメータを想定しています。「引数」フィールドで、次のように入力します デフォルト値のプロンプトが表示され、ここではデフォルト値を入力することをお薦めします。
${input} ${output}
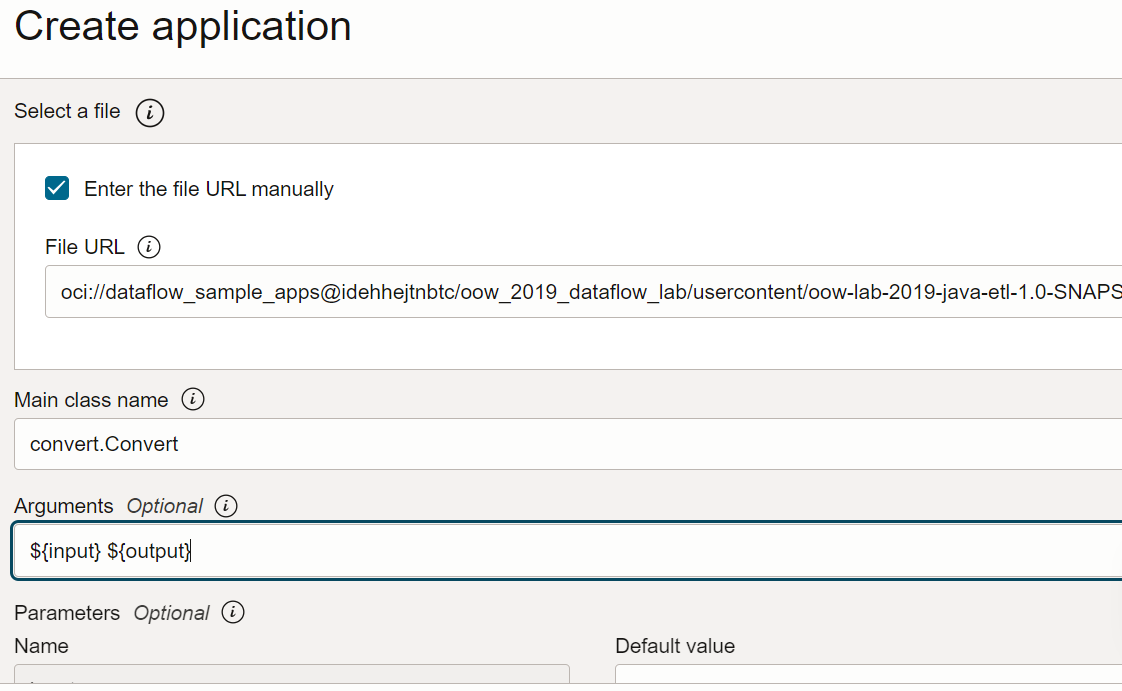
- ファイルURL: オブジェクト・ストレージ内のJARファイルの場所です。このアプリケーションの場所:
- 入力および出力引数は次のとおりです。
- 入力:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - 出力:
oci://<yourbucket>@<namespace>/optimized_listings
アプリケーションの構成を再確認して、次のようになっているかどうかを確認してください:
 ノート
ノート
テナント内のバケットを指すように出力パスをカスタマイズする必要があります。 - 入力:
- 完了したら、「作成」を選択します。アプリケーションが作成されると、「アプリケーション」リストに表示されます。
完了しました。最初のデータ・フロー・アプリケーションを作成しました。次に、これを実行できます。
spark-submitおよびCLIを使用して、Javaアプリケーションを作成します。
spark-submitおよびJava SDKを使用して、データ・フローでJavaアプリケーションを作成する演習を実行します。
これらのファイルは、この演習を実行するファイルであり、次のパブリック・オブジェクト・ストレージURIで使用できます。
- CSV形式の入力ファイル:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - JARファイル:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Javaアプリケーションを作成したので、それを実行できます。
- ステップを正確に実行した場合は、リストで自分のアプリケーションをハイライト表示し、「アクション」メニューを選択して「実行」をクリックするだけで済みます。
- アプリケーションを実行する前に、パラメータをカスタマイズする機能が提示されます。この場合は、前もって正確な値を入力したので、「実行」をクリックするだけで実行を開始できます。
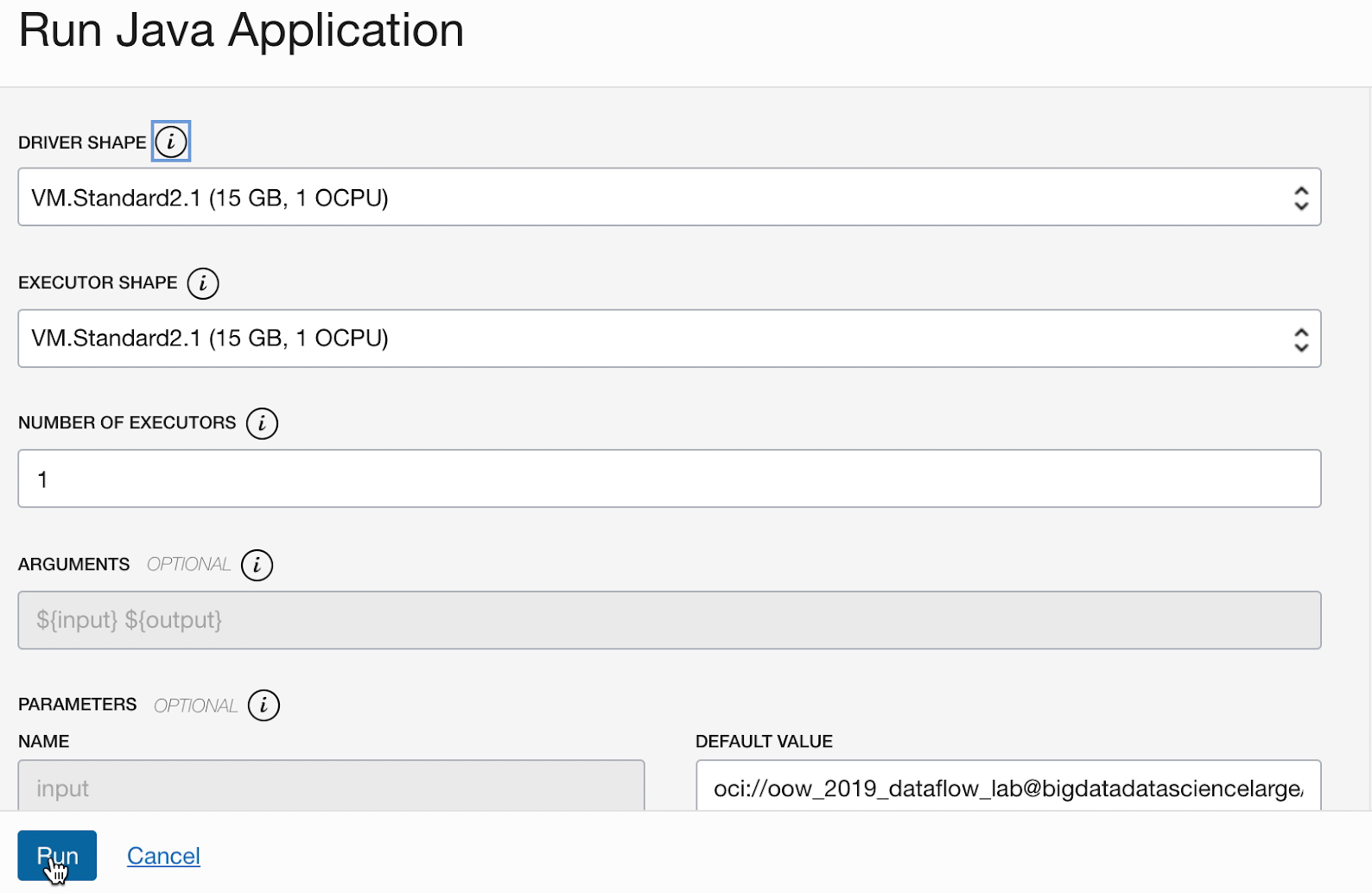
アプリケーションの実行中に、オプションで、進行状況をモニターするためにSpark UI をロードできます。該当する実行の「アクション」メニューから、「Spark UI」を選択します。
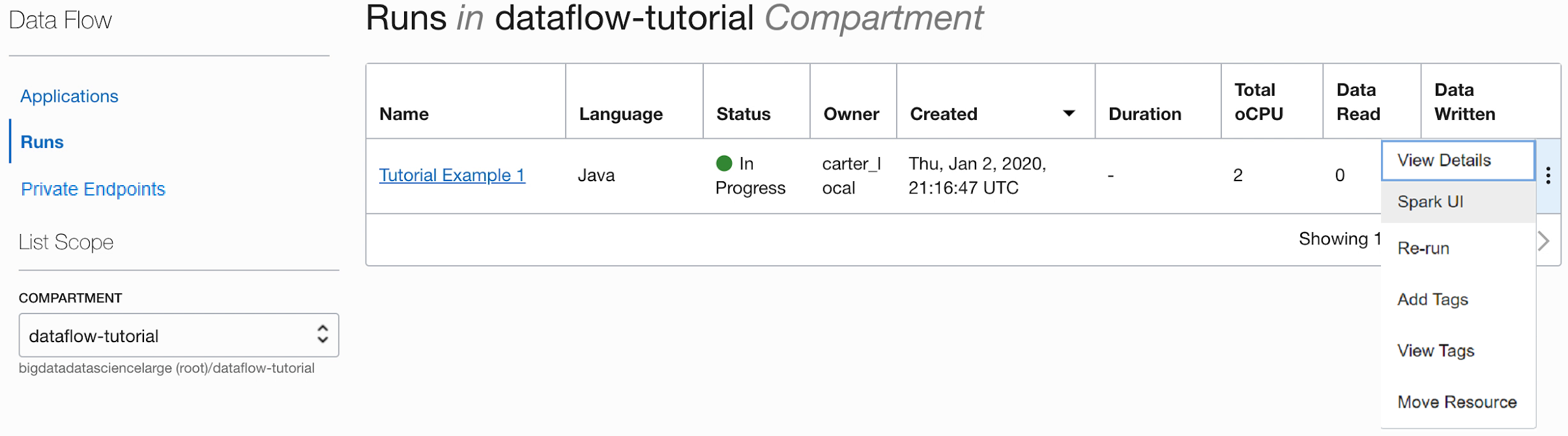
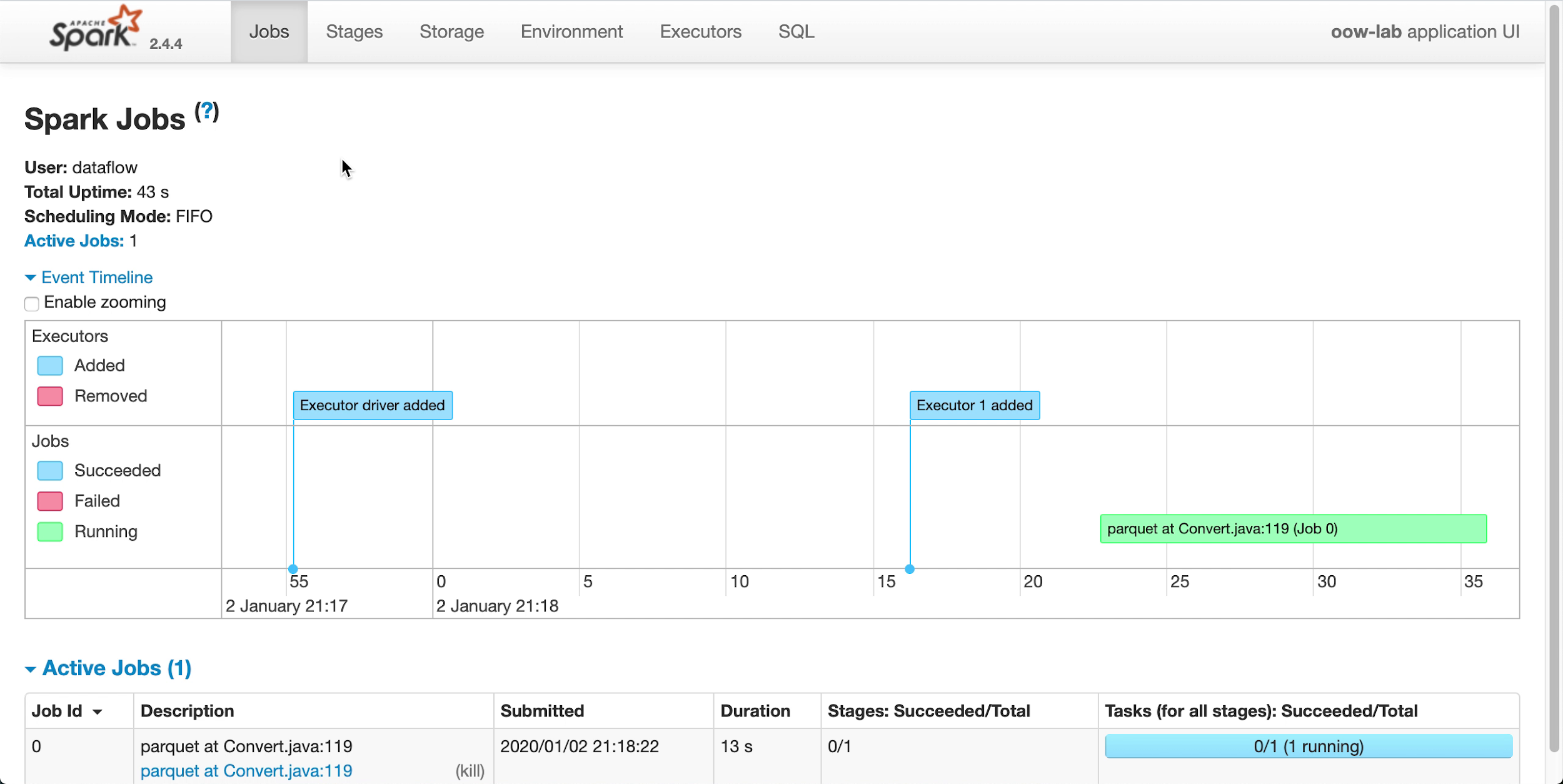
1分後、「実行」に
Succeededの状態で正常に終了したことが表示されます。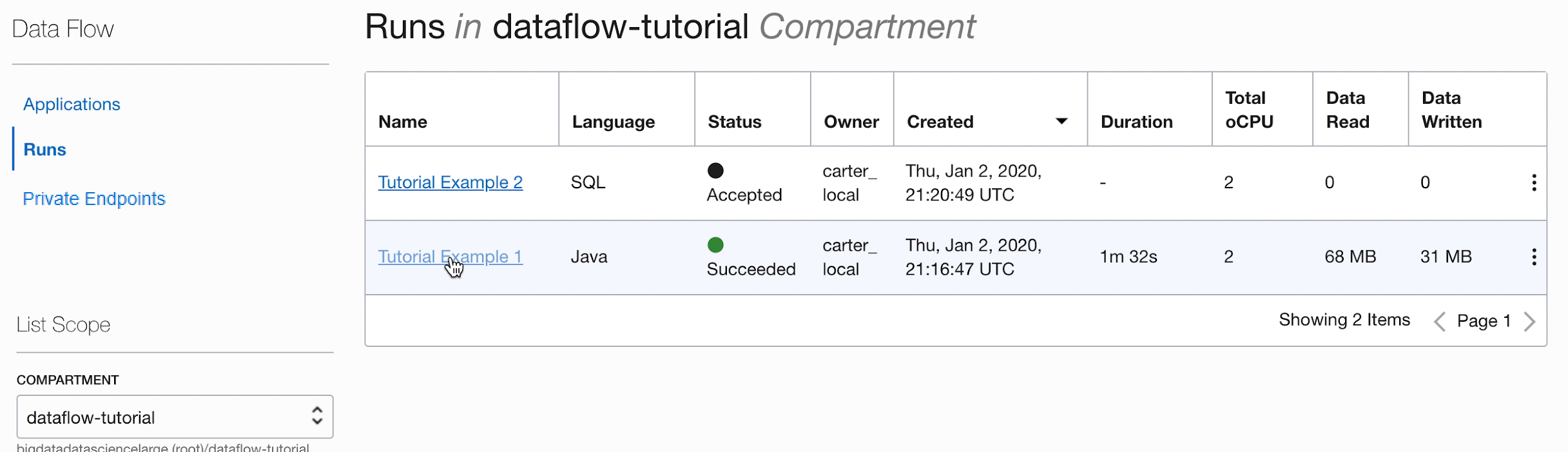
「実行」をドリルして追加の詳細を確認し、一番下までスクロールしてログのリストを表示します。

spark_application_stdout.log.gzファイルをクリックすると、ログ出力
Conversion was successfulが表示されます。
- 出力オブジェクト・ストレージ・バケットに移動して、新しいファイルが作成されたことを確認することもできます。
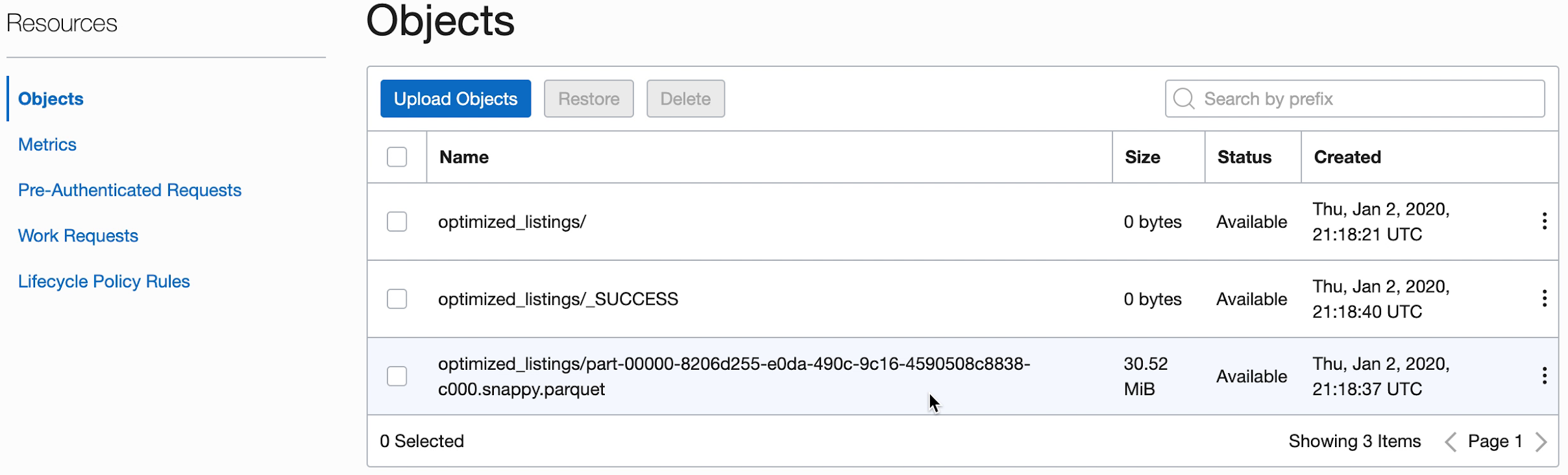
これらの新しいファイルは、後のアプリケーションで使用されます。次の演習に進む前に、バケットに表示されていることを確認します。
2. SparkSQLによる簡易化
この演習では、SQLスクリプトを実行して、データセットの基本的なプロファイリングを実行します。
この演習では、「1. Javaを使用したETL」で生成した出力を使用します。これを試す前に、正常に完了している必要があります。
ここでのステップは、コンソールUIを使用する場合のものです。この演習は、spark-submitをCLIから使用するか、spark-submitをJava SDKとともに使用して実行できます。
他のデータ・フロー・アプリケーションと同様に、SQLファイルはオブジェクト・ストレージに格納され、多数のSQLユーザーで共有されます。これを支援するために、データ・フローでは、SQLスクリプトをパラメータ化し、実行時にカスタマイズできます。他のアプリケーションと同様にデフォルト値をパラメータに指定でき、これらのスクリプトを実行する人の貴重な手がかりとなることがよくあります。
SQLスクリプトはデータ・フロー・アプリケーションで直接使用でき、コピーを作成する必要はありません。ここでスクリプトを再度示し、いくつかの点を説明します。
SparkSQLスクリプトのリファレンス・テキスト: 
- スクリプトは、必要なSQL表の作成から開始します。現在、データ・フローには永続SQLカタログがないため、すべてのスクリプトは必要な表を定義することから始まります。
- 表の場所は、
${location}として設定されます。これは、ユーザーが実行時に指定する必要があるパラメータです。これによりデータ・フローには、1つのスクリプトを使用して多くの様々な場所を処理し、様々なユーザー間でコードを共有する柔軟性が与えられます。このラボでは、演習1で使用した出力場所を指すように${location}をカスタマイズする必要があります - 前述のとおり、SQLスクリプトの出力は取得され、「実行」の下で使用できます。
- データ・フローで、SQLアプリケーションを作成し、タイプとして「SQL」を選択して、デフォルトのリソースを受け入れます。
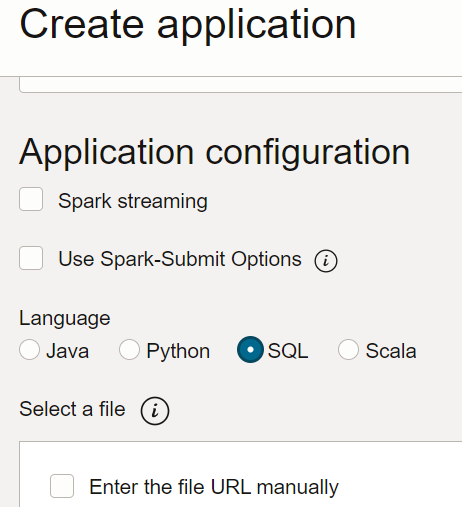
- 「アプリケーション構成」で、SQLアプリケーションを次のように構成します:
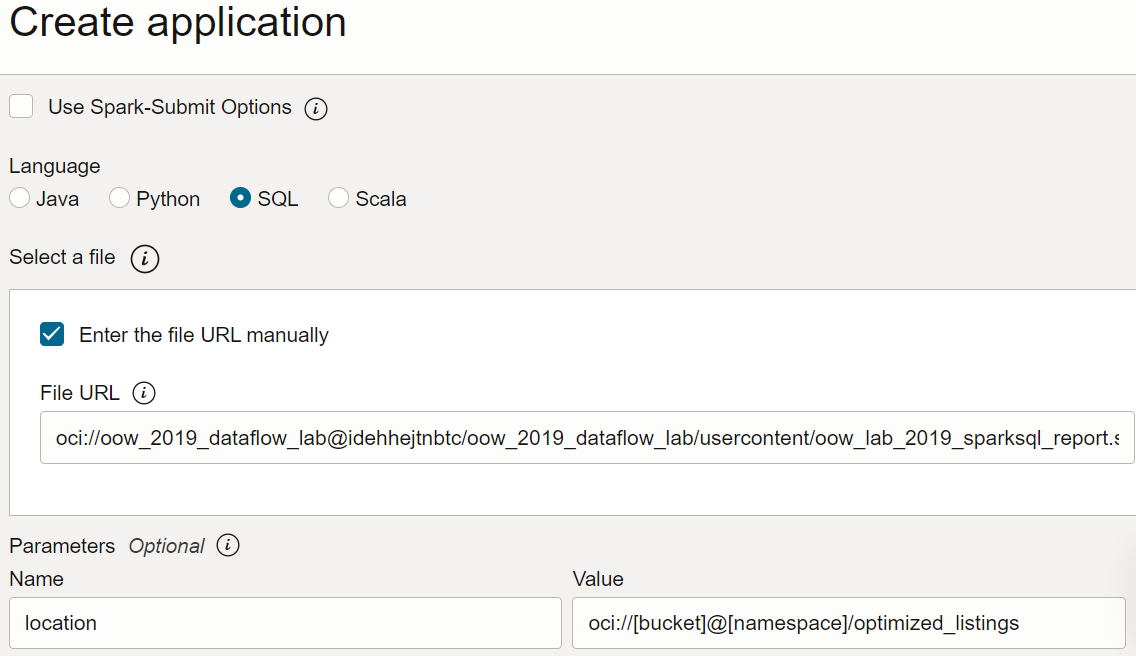
- ファイルURL: オブジェクト・ストレージ内のSQLファイルの場所です。このアプリケーションの場所:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql - 引数: SQLスクリプトでは、前のステップからの出力の場所である1つのパラメータを想定しています。「パラメータの追加」をクリックし、テンプレートに基づいて、ステップaで出力パスとして使用した値を入れて、
locationという名前のパラメータを入力しますoci://[bucket]@[namespace]/optimized_listings
完了したら、アプリケーション構成が次のようになっていることを確認します:
- ファイルURL: オブジェクト・ストレージ内のSQLファイルの場所です。このアプリケーションの場所:
- 場所の値をテナンシの有効なパスにカスタマイズします。
- アプリケーションを保存し、「アプリケーション」リストから実行します。
- 実行の完了後、実行を開きます。
- 実行ログに移動します:

- spark_application_stdout.log.gzを開き、出力が次の出力と一致していることを確認します。 ノート
図とは異なる順序で行が表示されることがありますが、値は一致する必要があります。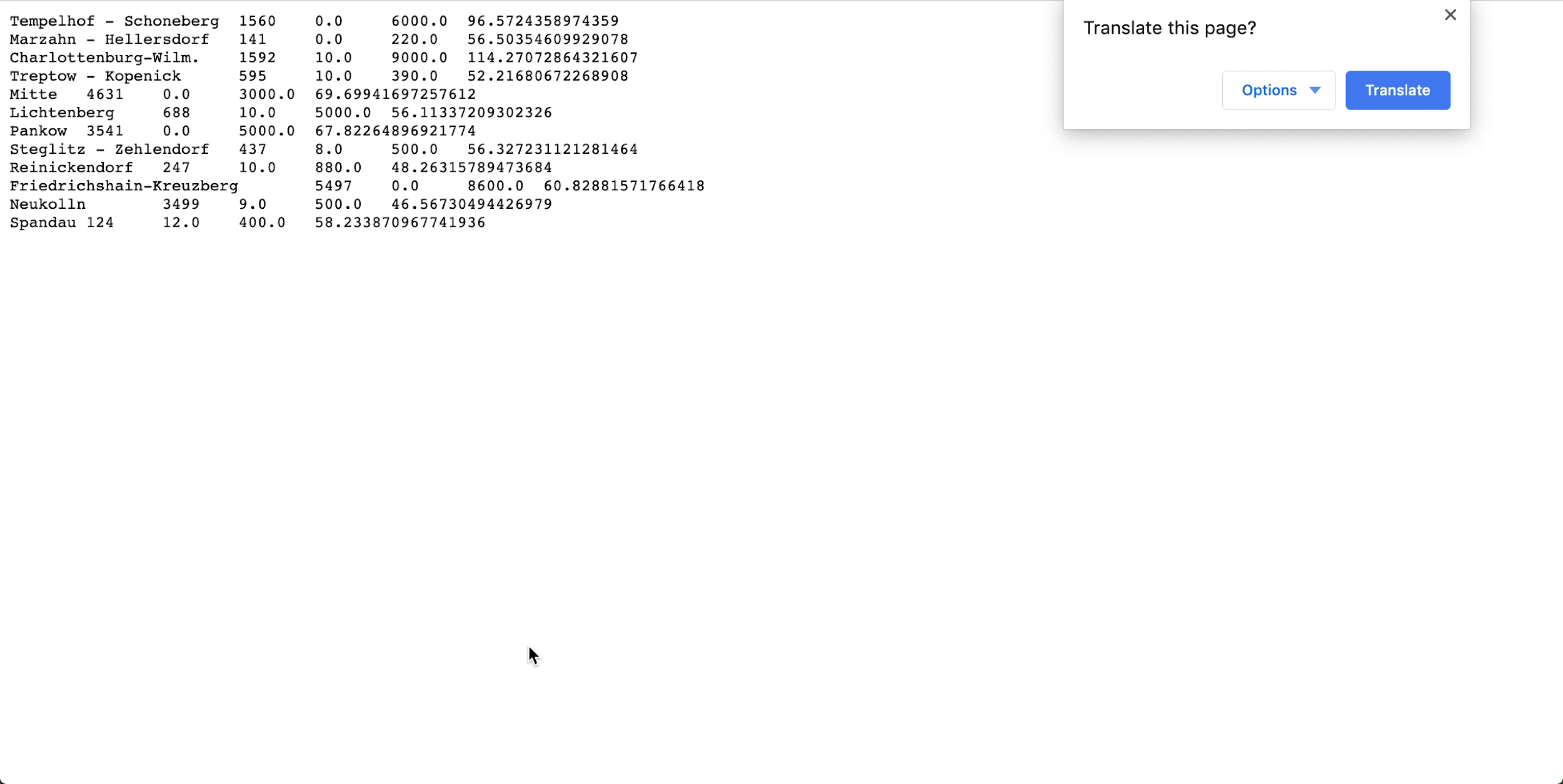
- SQLプロファイリングに基づき、このデータセットでは、Neukollnの平均定価は最低の$46.57で、Charlottenburg-Wilmersdorfは最大の$114.27です(ノート: ソース・データセットの価格はEURではなくUSDです)。
この演習では、データ・フローの重要な側面を示します。SQLアプリケーションを配置すると、クラスタの容量、データ・アクセスおよび保持、資格証明管理またはその他のセキュリティの考慮事項を心配することなく、誰でも簡単に実行できます。たとえば、ビジネス・アナリストはデータ・フローとともにSparkベースのレポートを簡単に使用できます。
3. PySparkを使用した機械学習
PySparkを使用して、入力データに対して単純な機械学習タスクを実行します。
この演習では、1. Javaを使用したETLからの出力を入力データとして使用します。この演習を試す前に、最初の演習を正常に完了する必要があります。ここでの目的は、Spark機械学習アルゴリズムを使用して、各種のAirbnbリストの中から最適な取引を識別することです。
ここでのステップは、コンソールUIを使用する場合のものです。この演習は、spark-submitをCLIから使用するか、spark-submitをJava SDKとともに使用して実行できます。
PySparkアプリケーションは、データ・フロー・アプリケーションで直接使用できます。コピーを作成する必要はありません。
次に、いくつかの点を説明するために、PySparkスクリプトのリファレンス・テキストを示します: 
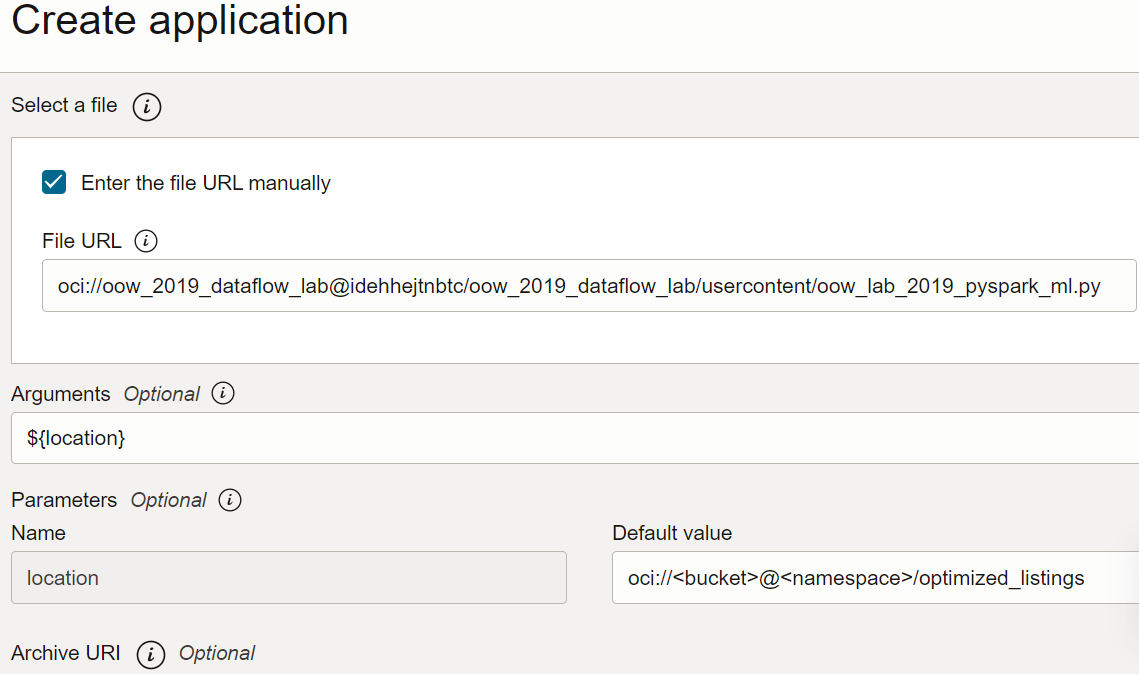
- Pythonスクリプトでコマンドライン引数(赤でハイライト表示)が必要です。データ・フロー・アプリケーションを作成する際、ユーザーが入力パスに設定するパラメータを作成する必要があります。
- このスクリプトは線形回帰を使用して、リスト当たりの価格を予測し、予測から定価を減算して最適な取引を検索します。最もマイナスの値は、モデルごとの最適値を示します。
- このスクリプトのモデルは簡略化されており、平方フィートのみが考慮されます。実際の設定では、近隣や他の重要な予測子変数など、より多くの変数を使用します。
コンソールから、またはコマンドラインからSpark-submitを使用して、あるいはSDKを使用して、PySparkアプリケーションを作成します。
コンソールを使用して、データ・フローにPySparkアプリケーションを作成します。
-
アプリケーションを作成し、Pythonタイプを選択します。
-
アプリケーションの構成を再確認して、次のようになっているかどうかを確認してください:
Spark-submitおよびCLIを使用して、データ・フローにPySparkアプリケーションを作成します。
Spark-submitおよびSDKを使用して、データ・フローにPySparkアプリケーションを作成します。
- 「アプリケーション」リストからアプリケーションを実行します。
「実行」が完了したらそれを開き、ログに移動します。

- spark_application_stdout.log.gzファイルを開きます。出力は次と同じになります:

この出力から、面積が4639平方フィートで定価$35.00に比べて、予測価格$313.70のリストID 690578が最適な取引であることがわかります。少し話が出来すぎで本当とは思えない場合は、一意のIDでデータにドリルバックして、これが本当の掘り出し物かどうかを正確に把握できます。この場合も、ビジネス・アナリストは、この機械学習アルゴリズムの出力を簡単に使用して、さらに分析を行うことができます。