データ・サイエンスのジョブ実行のスケジュール
このチュートリアルでは、データ統合を使用して、データ・サイエンス・ジョブのジョブ実行をスケジュールします。
主なタスクは:
- データ・サイエンス・ジョブ・アーティファクトを使用してジョブを作成します。
- RESTタスクを設定して、アーティファクトで作成されたジョブと同じ詳細を持つジョブを作成します。
- スケジュールを設定し、RESTタスクに割り当てます。
- タスク・スケジューラでデータ・サイエンス・ジョブを作成するようにします。
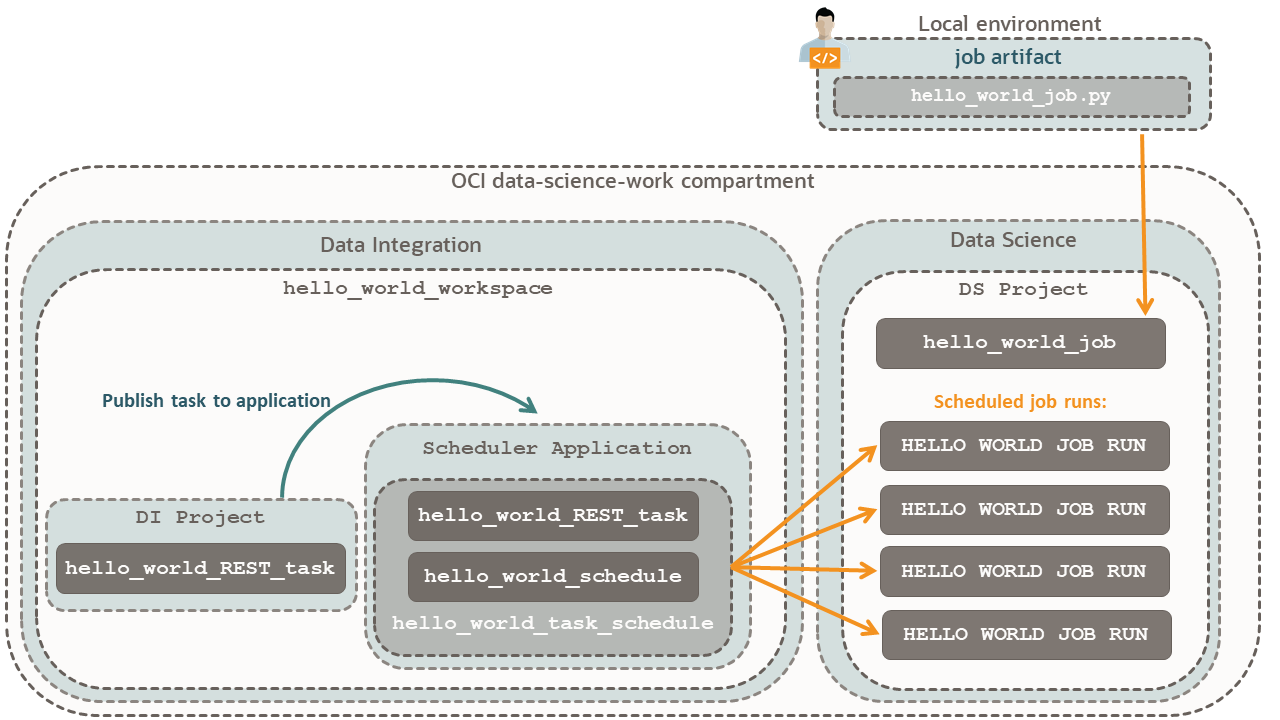
開始する前に
このチュートリアルを正常に実行するには、次が必要です:
-
支払済Oracle Cloud InfrastructureアカウントまたはOracle Cloudプロモーションの新しいアカウントは、無料Oracle Cloudプロモーションのリクエストおよび管理を参照してください。
- MacOS、LinuxまたはWindowsコンピュータ。
1. 準備
チュートリアル用の動的グループ、ポリシー、コンパートメントおよびデータ・サイエンス・プロジェクトを作成して設定します。
次の詳細を使用して、データ・サイエンス・テナンシの手動構成チュートリアルを実行します:
データ統合サービスによるワークスペースの作成を許可します。
このステップでは、data-science-dynamic-groupにデータ統合ワークスペースを追加します。data-science-dynamic-group-policyは、この動的グループのすべてのメンバーにdata-science-familyを管理することを許可します。これで、タスク・スケジュールなどのワークスペース・リソースで、データ・サイエンス・ジョブを作成できます。
2. ジョブ実行の設定
ジョブおよびジョブ実行で使用するhello world Pythonジョブ・アーティファクトを作成します:
hello_world_jobを実行します:
ジョブを作成するときに、そのジョブのインフラストラクチャおよびアーティファクトを設定します。次に、インフラストラクチャをプロビジョニングするジョブ実行を作成し、ジョブ・アーティファクトを実行し、ジョブが終了したら、使用されているリソースをプロビジョニング解除および破棄します。
-
hello_world_jobページで、「ジョブ実行の開始」をクリックします。 -
data-science-workコンパートメントを選択します。 -
ジョブ実行に
hello_world_job_run_testという名前を付けます。 - 「ロギング構成のオーバーライド」および「ジョブ構成のオーバーライド」セクションをスキップします。
- 「開始」をクリックします。
- 現在のページ(現在はジョブ実行の詳細ページ)が表示されるトレイルで、「ジョブ実行」をクリックし、戻ってジョブ実行のリストを取得します。
- hello_world_job_run_testについて、ステータスが受入れ済から進行中に変わり、最後に成功に変わるのを待ってから、次の手順に進みます。
hello_world_jobをスケジューリングに使用するには、ジョブに関するいくつかの情報を準備する必要があります:
3. タスクの設定
コンポーネントの視覚的な関係については、スケジューラ図を参照してください。
ジョブ実行を作成するタスクを使用してプロジェクトをホストするワークスペースを作成します。
このワークスペースではdatascience-vcnが使用され、作成したデータ・サイエンス・ジョブでは、データ・サイエンスが提供する「デフォルト・ネットワーキング」オプションが使用されます。データ統合サービスにdata-science-workコンパートメント内のすべてのリソースへのアクセス権を付与したため、VCNが異なっていても問題ありません。データ統合にはdatascience-VCNにスケジューラがあり、デフォルト・ネットワーキングVCNでジョブ実行を作成します。
hello_world_workspaceで、システム生成プロジェクト名を更新します。
このプロジェクトがデータ統合プロジェクトであり、データ・サイエンス・プロジェクトではないことが明確になるように、プロジェクト名を変更します。
タスクを作成し、ジョブ実行を作成するためのREST APIパラメータを定義します。
RESTタスクが正常に作成されたことがワークスペースに表示された後、「保存して閉じる」をクリックします。
RESTタスクのリクエスト本文で、ジョブ実行の作成に必要なパラメータに値を割り当てます。このチュートリアルの「ジョブの作成」セクションで、データ・サイエンスで作成した
hello_world_jobと同じ値を使用します。参照:
スケジュールに従ってRESTタスクを実行するスケジューラ・アプリケーションを作成します。
-
hello_world_workspaceワークスペースの「クイック・アクション」パネルで、「アプリケーションの作成」をクリックします。 -
アプリケーションに
Scheduler Applicationという名前を付けます。 - 「作成」をクリックします。
hello_world_REST_taskをScheduler Applicationに追加します:
-
現在のページを表示する証跡で、
hello_world_workspaceワークスペースに移動し、「プロジェクト」リンクをクリックします。 - 「DIプロジェクト」をクリックします。
- 「タスク」をクリックします。
-
「タスク」のリストで、
hello_world_REST_taskの「アクション」メニューをクリックし、「アプリケーションに公開」をクリックします。 - 「アプリケーション名」で、「Scheduler Application」をクリックします。
- 「発行」をクリックします
hello_world_REST_taskをスケジュールする前に、タスクを手動で実行してテストします:
4. タスクのスケジュールと実行
公開されたhello_world_REST_taskを実行するスケジュールを作成します。
- このステップでは、
Scheduler Applicationでスケジュールを設定します。次のステップでは、スケジュールをhello_world_REST_taskに関連付けます。
参照: 公開済タスクのスケジュール
公開されたhello_world_REST_taskにhello_world_scheduleを割り当てます:
データ・サイエンス・ジョブ実行に、データ統合からのスケジュール済タスクが表示されることを確認します。
1つ以上のジョブ実行を受け取ったら、このチュートリアルは完了です。これで、スケジューラを無効にして、新しいジョブ実行を停止できます。
-
hello_world_workspaceで、「アプリケーション」、「Scheduler Application」の順にクリックします。 - 左側のナビゲーション・パネルで、「タスク」をクリックします。
-
hello_world_REST_taskをクリックします。 -
タスク・スケジュールのリストで、
hello_world_REST_task_scheduleをクリックします。 - 「無効化」をクリックします
- 確認ダイアログで「無効化」をクリックします。
- このチュートリアル用に複数のタスク・スケジュールを作成した場合は、そのすべてを無効にします。
次の手順
データ・サイエンス・ジョブ実行が正常にスケジュールされました。
データ・サイエンス・ジョブの詳細は、データ・サイエンスのドキュメントの次のセクションを参照してください:
データ・サイエンスの詳細は、データ・サイエンス・チュートリアルおよびデータ・サイエンス学習ビデオを参照してください。