ジョブのバッチ推論
ジョブで使用する様々なタイプのバッチ推論の使用方法について学習します。
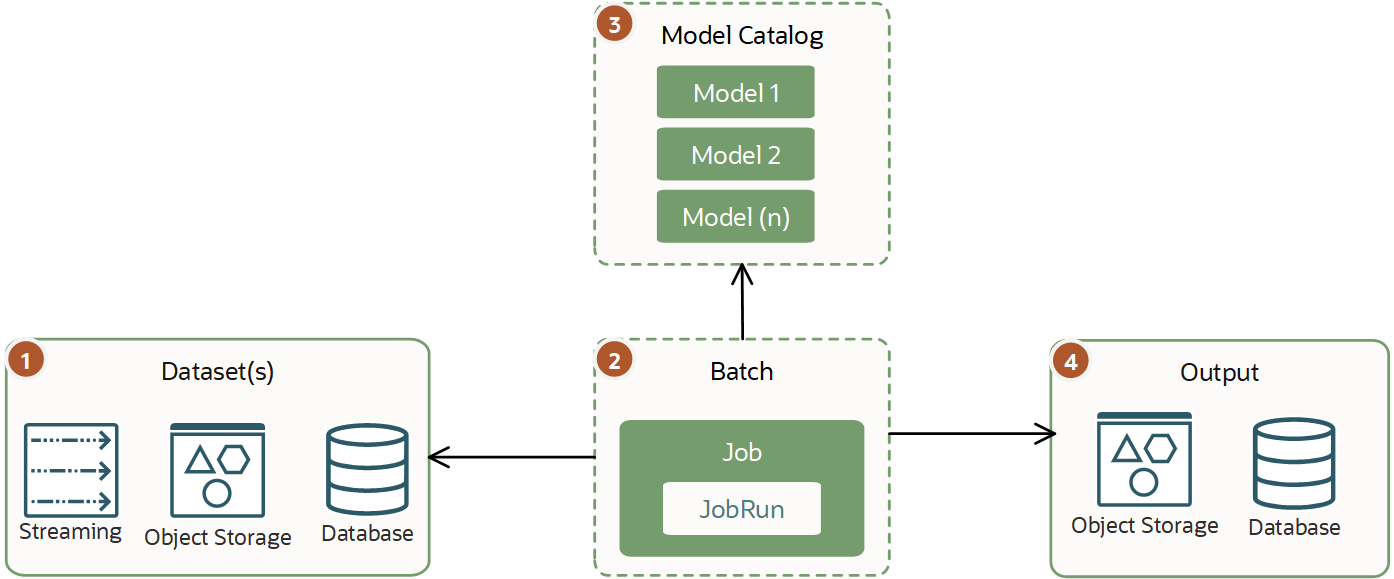
従来のバッチ推測は、既存のモデルと観測に基づいて予測を実行してから出力を格納する非同期プロセスです。このバッチ推論は、データ・サイエンス・ジョブで実行できる単一の仮想マシン・ジョブです。
通常、ワークロードは様々ですが、ミニ・バッチ推論よりも大きいため、終了までに数時間または数日かかる場合があります。このタイプのワークロードでは、リアルタイムまたはほぼリアルタイムの結果を生成する必要はありません。実行に必要なCPUまたはGPUおよびメモリーに関する大規模な要件がある場合があります。
最適なパフォーマンスを得るには、AIおよびMLモデルをHTTPまたは別のネットワーク経由でコールするかわりに、直接使用します。大規模なデータセットを使用する大量の処理が必要な場合は、モデルを直接使用することが特に重要です。たとえば、画像の処理です。
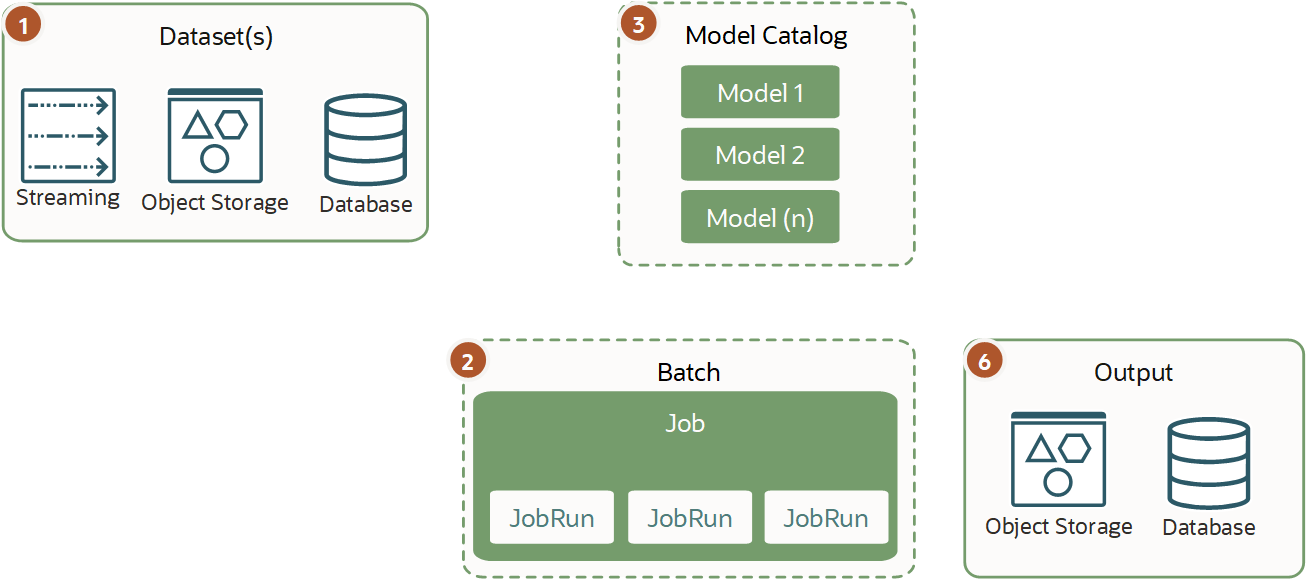
ミニ・バッチ推論
ミニ・バッチ推論はバッチ推論と似ていますが、複数のジョブまたは複数の小さなタスクを同時に実行する1つのジョブを使用する小さなバッチにタスクを分割できる点が異なります。
タスクは小さく、ミニ・バッチは定期的に実行されるため、実行時間は通常は数分間のみです。このタイプのワークロードは、スケジューラまたはトリガーを使用して定期的に実行され、小規模なデータ・グループを処理します。ミニ・バッチ処理を使用すると、データや推論の小片を段階的にロードして処理できます。
最適なパフォーマンスが必要な場合、モデル・カタログのモデルに対してミニ・バッチを実行できます。通常、ワークロードとデータ入力はそれほど大きくないためです。
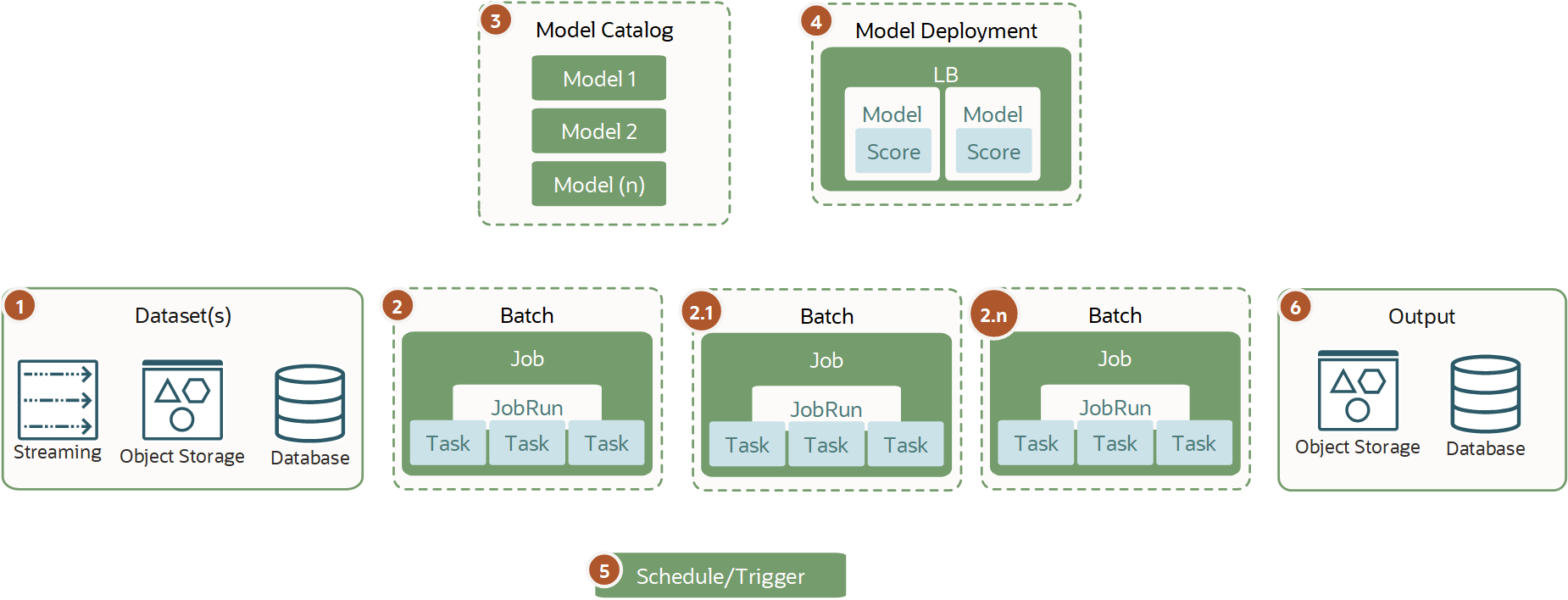
分散バッチ推論
負荷の高いジョブには分散バッチ推論を使用します。
分散バッチ推論と分散モデル・トレーニングは異なります。また、通常、バッチ推論時にのみインフラストラクチャをプロビジョニングして使用し、完了時に自動的に破棄するため、モデル・デプロイメント・タイプの推論ではありません。
分散バッチ推論は、単一のVMまたはBMでタイムリに処理できず、水平方向のスケーリングを必要とする大規模なデータセットおよび重い推論で必要です。1つまたは複数のジョブ構成で(1+n)ジョブ実行を様々なタイプのインフラストラクチャで実行し、データセットを分割できます。このタイプのワークロードは、ジョブを使用してインフラストラクチャ・メモリーとCPUまたはGPUを最大限に使用して、モデル・カタログから直接AIおよびMLモデルに対して作業するときに最高のパフォーマンスを提供します。
バッチ推論ワークロードの比較
様々なタイプのワークロードと、対応するバッチ推論のタイプの大まかな比較:
|
バッチ推論 |
ミニ・バッチ推論 |
分散バッチ推論 |
|
|---|---|---|---|
|
インフラストラクチャ |
大きい |
軽量から中程度 |
非常に大きい |
|
VM |
単一 |
単一または複数(小規模) |
多 |
|
プロビジョニング速度 - 必須 |
中程度 |
高速 |
平均から低速 |
|
スケジューラ - 必須 |
はい |
はい |
ユース・ケースに依存 |
|
トリガー - 必須 |
はい |
はい |
いいえ |
|
ワークロード |
大きい |
軽い |
大きい、または重い |
|
データセット・サイズ |
大きい |
小さい |
非常に大きい、または自動スケーリング |
|
バッチ・プロセス時間(推定。ただし、ユース・ケースによって異なる場合があります) |
中程度から非常に長い(2桁の分数から数日または数時間のプロセス) |
短い、またはほぼリアルタイム |
中程度から非常に長い(数時間から数日間) |
|
モデル・デプロイメント |
不要 |
はい、ただし必須ではありません |
不要 |
|
エンドポイント |
いいえ |
いいえ |
いいえ |