Using JupyterHub in Big Data Service 3.0.27 or Later
Use JupyterHub to manage Big Data Service 3.0.27 or later ODH 2.x notebooks for groups of users.
Prerequisites
Accessing JupyterHub
- Access Apache Ambari.
- From the side toolbar, under Services select JupyterHub.
Manage JupyterHub
A JupyterHub admin user can perform the following tasks to manage notebooks in JupyterHub on Big Data Service 3.0.27 or later ODH 2.x nodes.
To manage Oracle Linux 7 services with the systemctl command, see Working With System Services.
To sign in an Oracle Cloud Infrastructure instance, see Connecting to Your Instance.
As an admin, you can stop or disable JupyterHub so it doesn't consume resources, such as memory. Restarting might also help with unexpected issues or behavior.
Stop or start JupyterHub through Ambari for Big Data Service 3.0.27 or later clusters.
As an admin, you can add JupyterHub Server to a Big Data Service node.
This is available for Big Data Service 3.0.27 or later clusters.
- Access Apache Ambari.
- From the side toolbar, select Hosts.
- To add JupyterHub Server, select a host where JupyterHub isn't installed.
- Select Add.
- Select JupyterHub Server.
As an admin, you can move JupyterHub Server to a different Big Data Service node.
This is available for Big Data Service 3.0.27 or later clusters.
- Access Apache Ambari.
- From the side toolbar, under Services select JupyterHub.
- Select Actions, and then select Move JupyterHub Server.
- Select Next.
- Select the host to move JupyterHub Server to.
- Complete the move wizard.
As an admin, you can run JupyterHub service/health checks through Ambari.
This is available for Big Data Service 3.0.27 or later clusters.
- Access Apache Ambari.
- From the side toolbar, under Services select JupyterHub.
- Select Actions, and then select Run Service Check.
Manage Users and Permissions
Use one of the two authentication methods to authenticate users to JupyterHub so that they can create notebooks, and optionally administer JupyterHub on Big Data Service 3.0.27 or later ODH 2.x clusters.
JupyterHub users must be added as OS users on all Big Data Service cluster nodes for Non-Active Directory (AD) Big Data Service clusters, where users aren't automatically synced across all cluster nodes. Administrators can use the JupyterHub User Management script to add users and groups before signing in to JupyterHub.
Prerequisite
Complete the following before accessing JupyterHub:
- SSH sign in to the node where JupyterHub is installed.
- Navigate to
/usr/odh/current/jupyterhub/install. - To provide the details of all users and groups in the
sample_user_groups.jsonfile, run:sudo python3 UserGroupManager.py sample_user_groups.json Verify user creation by executing the following command: id <any-user-name>
Supported Authentication Types
- NativeAuthenticator: This authenticator is used for small or medium-sized JupyterHub applications. Sign up and authentication are implemented as native to JupyterHub without relying on external services.
-
SSOAuthenticator: This authenticator provides a subclass of
jupyterhub.auth.Authenticatorthat acts as an SAML2 Service Provider. Direct it to an appropriately configured SAML2 Identity Provider and it enables single sign-on for JupyterHub.
Native authentication depends on the JupyterHub user database for authenticating users.
Native authentication applies to both HA and non-HA clusters. Refer native authenticator for details on the native authenticator.
These prerequisites must be met to authorize a user in a Big Data Service HA cluster using native authentication.
These prerequisites must be met to authorize a user in a Big Data Service non-HA cluster using native authentication.
Admin users are responsible for configuring and managing JupyterHub. Admin users are also responsible for authorizing newly signed up users on JupyterHub.
Before adding an admin user, the prerequisites must be met for an non-HA cluster.
- Access Apache Ambari.
- From the side toolbar, under Services select JupyterHub.
- Select Configs, and then select Advanced Configs.
- Select Advanced jupyterhub-config.
-
Add admin user to
c.Authenticator.admin_users. - Select Save.
Before adding other users, the prerequisites must be met for a Big Data Service cluster.
-
Admin user must sign in JupyterHub and from the new menu option to authorize signed in users, authorise the new user.
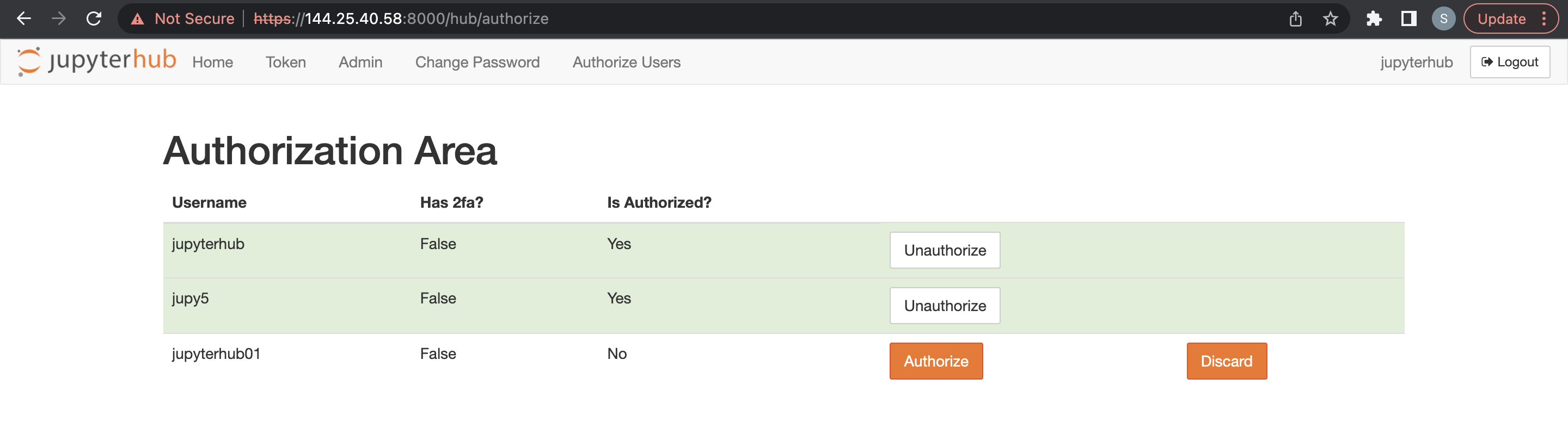
An admin user can delete JupyterHub users.
- Access JupyterHub.
- Open File > HubControlPanel.
- Navigate to the Authorize Users page.
- Delete the users you want to remove.
You can use LDAP authentication through Ambari for Big Data Service 3.0.27 or later ODH 2.x clusters.
Using LDAP Authentication Using Ambari
To use LDAP authenticator, you must update the JupyterHub config file with the LDAP connection details.
Use Ambari for LDAP authentication on Big Data Service 3.0.27 or later clusters.
Refer LDAP authenticator for details on the LDAP authenticator.
pConfigure SSO Auth in Big Data Service 3.0.27 or later ODH 2.x JupyterHub service.
You can use Oracle Identity Domain to set up SSO Auth in Big Data Service 3.0.27 or later ODH 2.x JupyterHub clusters.
You can use OKTA to set up SSO Auth in Big Data Service 3.0.27 or later ODH 2.x JupyterHub clusters.
As an admin, you can manage JupyterHub configurations through Ambari for Big Data Service 3.0.27 or later ODH 2.x clusters.
Spawning Notebooks
The following Spawner configurations are supported on Big Data Service 3.0.27 and later ODH 2.x clusters.
Complete the following:
- Native Authentication:
- Sign in using signed in user credentials
- Enter username.
- Enter password.
- Using SamlSSOAuthenticator:
- Sign in with SSO sign in.
- Complete sign in with the configured SSO application.
Spawning Notebooks on an HA Cluster
For AD integrated cluster:
- Sign in using either of the preceding methods. The authorization works only if the user is present on the Linux host. JupyterHub searches for the user on the Linux host while trying to spawn the notebook server.
- You're redirected to a Server Options page where you must request a Kerberos ticket. This ticket can be requested using either Kerberos principal and the keytab file, or the Kerberos password. The cluster admin can provide the Kerberos principal and the keytab file, or the Kerberos password. The Kerberos ticket is needed to get access on the HDFS directories and other big data services that you want to use.
Spawning Notebooks on a non-HA Cluster
For AD integrated cluster:
Sign in using either of the preceding methods. The authorization works only if the user is present on the Linux host. JupyterHub searches for the user on the Linux host while trying to spawn the notebook server.
- Configure SSH keys/ Access tokens for the Big Data Service cluster node.
- Select notebook persistence mode as Git.
To set up Git connection for JupyterHub, complete the following:
- Access tokens for the Big Data Service cluster node.
- Select notebook persistence mode as Git
Generating SSH Key Pair
Using Access Tokens
You can use access tokens in the following ways:
- GitHub:
- Sign in to your GitHub account.
- Navigate to the Settings > Developer settings > Personal access tokens.
- Generate a new access token with the appropriate permissions.
- Use the access token as your password when prompted for authentication.
- GitLab:
- Sign in to your GitHub account.
- Navigate to the Settings > Access Tokens.
- Generate a new access token with the appropriate permissions.
- Use the access token as your password when prompted for authentication.
- BitBucket:
- Sign in to your BitBucket account.
- Navigate to the Settings > App passwords.
- Generate a new app password token with the appropriate permissions.
- Use the new app password as your password when prompted for authentication.
Selecting Persistence Mode as Git
- Access Apache Ambari.
- From the side toolbar, under Services select JupyterHub.
- Select Configs, and then select Settings.
- Search for Notebook persistence mode, and then select Git from the dropdown.
- Select Actions, and then select Restart All.
- Access Apache Ambari.
- From the side toolbar, under Services select JupyterHub.
- Select Configs, and then select Settings.
- Search for Notebook persistence mode, and then select HDFS from the dropdown.
- Select Actions, and then select Restart All.
As an admin user, you can store the individual user notebooks in Object Storage instead of HDFS. When you change the content manager from HDFS to Object Storage, the existing notebooks aren't copied over to Object Storage. The new notebooks are saved in Object Storage.
Mounting Oracle Object Storage Bucket Using rclone with User Principal Authentication
You can mount Oracle Object Storage using rclone with User Principal Authentication (API Keys) on a Big Data Service cluster node using rclone and fuse3, tailored for JupyterHub users.
Manage Conda Environments in JupyterHub
You can manage Conda environments on Big Data Service 3.0.28 or later ODH 2.x clusters.
- Create a conda environment with specific dependencies and create four kernels (Python/PySpark/Spark/SparkR) which point to the created conda environment.
- Conda environments and kernels created using this operation are available to all notebook server users.
- Separate create conda env operation is to decouple the operation with restart of service.
- JupyterHub is installed through the Ambari UI.
- Verify internet access to the cluster to download dependencies during conda creation.
- Conda environments and kernels created using this operation are available to all notebook server users.'
- Provide:
- Conda additional configs to avoid conda creation failure. For more information, see conda create.
- Dependencies in the standard requirements
.txtformat. - A conda env name that doesn't exist.
- Manually delete conda envs or kernels.
This operation creates a conda environment with specified dependencies and creates the specified kernel (Python/PySpark/Spark/SparkR) pointing to the created conda environment.
- If the specified conda env already exists, then the operation proceeds to the kernel creation step directly
- Conda environments or kernels created using this operation are available only to a specific user
- Manually run the python script
kernel_install_script.pyin sudo mode:'/var/lib/ambari-server/resources/mpacks/odh-ambari-mpack-2.0.8/stacks/ODH/1.1.12/services/JUPYTER/package/scripts/'Example:
sudo python kernel_install_script.py --conda_env_name conda_jupy_env_1 --conda_additional_configs '--override-channels --no-default-packages --no-pin -c pytorch' --custom_requirements_txt_file_path ./req.txt --kernel_type spark --kernel_name spark_jupyterhub_1 --user jupyterhub
Prerequisites
- Verify internet access to the cluster to download dependencies during conda creation. Otherwise, the creation fails.
- If a kernel with name
--kernel_nameexists, then an exception is thrown. - Provide the following:
- Conda configs to avoid creation failure. For more information, see https://conda.io/projects/conda/en/latest/commands/create.html.
- Dependencies provided in the standard requirements
.txtformat.
- Manually delete conda envs or kernels for any user.
Available Configs for Customization
-
--user(mandatory): OS and JupyterHub user for whom kernel and conda env is created. -
--conda_env_name(mandatory): Provide a unique name for the conda environment each time a new en is created for--user. -
--kernel_name: (mandatory) Provide a unique kernel name. -
--kernel_type: (mandatory) Must be one of the following (python / PysPark / Spark / SparkR) -
--custom_requirements_txt_file_path: (optional) If any Python/R/Ruby/Lua/Scala/Java/JavaScript/C/C++/FORTRAN and so on, dependencies are installed using conda channels, you must specify those libraries in a requirements.txtfile and provide the full path.For more information on a standard format to define requirements
.txtfile, see https://pip.pypa.io/en/stable/reference/requirements-file-format/. -
--conda_additional_configs: (optional)- This field provides additional parameters to be appended to the default conda creation command.
- The default conda creation command is:
'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8'. - If
--conda_additional_configsis given as'--override-channels --no-default-packages --no-pin -c pytorch', then, the final conda creation command run is'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8 --override-channels --no-default-packages --no-pin -c pytorch'.
Setting Up User-Specific Conda Environment
Create a Load Balancer and Backend Set
For more information creating backend sets, see Creating a Load Balancer Backend Set.
For more information on creating a public Load Balancer, see Creating a Load Balancer, and complete the following details.
For more information on creating a public Load Balancer, see Creating a Load Balancer, and complete the following details.
- Open the navigation menu, select Networking, and then select Load balancers. Select Load balancer. The Load balancers page appears.
- Select the Compartment from the list. All load balancers in that compartment are listed in tabular form.
- Select the load balancer to which you want to add a backend. The load balancer's details page appears.
- Select Backend sets, and then select the Backend set you created in Creating the Load Balancer.
- Select IP addresses, and then enter the required private IP address of the cluster.
- Enter 8000 for the Port.
- Select Add.
For more information on creating a public Load Balancer, see Creating a Load Balancer, and complete the following details.
-
Open a browser and enter
https://<loadbalancer ip>:8000. - Select the Compartment from the list. All load balancers in that compartment are listed in tabular form.
- Be sure it redirects to one of the JupyterHub servers. To verify, open a terminal session on the JupyterHub to find which node has been reached.
- After add node operation, cluster admin must manually update Load Balancer host entry in the newly added nodes. Applicable to all the node additions to cluster. For example, worker node, compute only, and nodes.
- Certificate must be manually updated to Load Balancer in case of expiry. This step ensures Load Balancer isn't using stale certificates and avoids health check/communication failures to backend sets. For more information, see Updating an Expiring Load Balancer Certificate to update expired certificate.
Launch Trino-SQL Kernels
JupyterHub PyTrino kernel provides an SQL interface that allows you to run Trino queries using JupyterHub SQL. This is available for Big Data Service 3.0.28 or later ODH 2.x clusters.
For more information on SqlMagic parameters, see https://jupysql.ploomber.io/en/latest/api/configuration.html#changing-configuration.