ビッグ・データ・サービス3.0.26以前でのJupyterHubの使用
JupyterHubを使用して、ユーザーのグループのビッグ・データ・サービス3.0.26以前のODH 1.xノートブックを管理します。
前提条件
ブラウザからJupyterHubにアクセスする前に、管理者は次を実行する必要があります:
- ユーザーからの受信接続でノードを使用できるようにします。ノードのプライベートIPアドレスをパブリックIPアドレスにマップする必要があります。あるいは、要塞ホストまたはOracle FastConnectを使用するようにクラスタを設定できます。プライベートIPアドレスを使用したクラスタ・ノードへの接続を参照してください。
- ノードでポート
8000を開くには、ネットワーク・セキュリティ・リストにイングレス・ルールを構成します。セキュリティ・ルールの定義を参照してください。
JupyterHubデフォルト資格証明
ビッグ・データ・サービス3.0.21以前のJupyterHubのデフォルトの管理サインイン資格証明は次のとおりです:
- ユーザー名:
jupyterhub - パスワード: Apache Ambari管理パスワード。これは、クラスタの作成時に指定されたクラスタ管理者パスワードです。
- HAクラスタのプリンシパル名:
jupyterhub - HAクラスタのkeytab:
/etc/security/keytabs/jupyterhub.keytab
ビッグ・データ・サービス3.0.22から3.0.26のJupyterHubのデフォルトの管理サインイン資格証明は次のとおりです。
- ユーザー名:
jupyterhub - パスワード: Apache Ambari管理パスワード。これは、クラスタの作成時に指定されたクラスタ管理者パスワードです。
- HAクラスタのプリンシパル名:
jupyterhub/<FQDN-OF-UN1-Hostname> - HAクラスタのkeytab:
/etc/security/keytabs/jupyterhub.keytab例:Principal name for HA cluster: jupyterhub/pkbdsv2un1.rgroverprdpub1.rgroverprd.oraclevcn.com Keytab for HA cluster: /etc/security/keytabs/jupyterhub.keytab
管理者は、追加のユーザーとそのサインイン資格証明を作成し、それらのユーザーにサインイン資格証明を提供します。詳細は、ユーザーと権限の管理を参照してください。
他のタイプの管理者であると明示的に言及されていないかぎり、この項で使用されているadministratorまたはadmin (管理者)は、JupyterHubの管理者であるjupyterhubを指します。
JupyterHubへのアクセス
または、「クラスタURL」の「クラスタ詳細」ページからJupyterHubリンクにアクセスできます。
ロード・バランサを作成して、JupyterHubなどのサービスにアクセスするためのセキュアなフロント・エンドを提供することもできます。ロード・バランサを使用したクラスタ上のサービスへの接続を参照してください。
ノートブックの生成
ユーザーがノートブックを生成するには、前提条件が満たされている必要があります。
- JupyterHubにアクセスします。
- 管理資格証明でサインインします。この認可は、ユーザーがLinuxホストに存在する場合にのみ機能します。JupyterHubは、ノートブック・サーバーの起動の試行中にLinuxホストでユーザーを検索します。
- 「Server Options」ページにリダイレクトされ、Kerberosチケットをリクエストする必要があります。このチケットは、Kerberosプリンシパルとkeytabファイル、またはKerberosパスワードを使用してリクエストできます。クラスタ管理者は、Kerberosプリンシパルとkeytabファイル、またはKerberosパスワードを提供できます。
Kerberosチケットは、使用するHDFSディレクトリおよびその他のビッグ・データ・サービスにアクセスする必要があります。
ユーザーがノートブックを生成するには、前提条件が満たされている必要があります。
- JupyterHubにアクセスします。
- 管理資格証明でサインインします。この認可は、ユーザーがLinuxホストに存在する場合にのみ機能します。JupyterHubは、ノートブック・サーバーの起動の試行中にLinuxホストでユーザーを検索します。
JupyterHubの管理
JupyterHub adminユーザーは、次のタスクを実行して、ビッグ・データ・サービス3.0.26以前のODH 1.xノードでJupyterHubのノートブックを管理できます。
adminとして、JupyterHubを構成できます。
ビッグ・データ・サービス3.0.26以前のクラスタのブラウザを使用してJupyterHubを構成します。
Big Data Service 3.0.26以前のクラスタのブラウザでJupyterHubを停止または起動します。
adminとして、メモリーなどのリソースを消費しないように、アプリケーションを停止または無効化できます。予期しない問題や動作が発生した場合は、再起動すると解決することがあります。
管理者は、ビッグ・データ・サービス・クラスタ内のアクティブなノートブック・サーバーの数を制限できます。
デフォルトでは、ノートブックはクラスタのHDFSディレクトリに格納されます。
HDFSディレクトリhdfs:///user/<username>/へのアクセス権が必要です。ノートブックはhdfs:///user/<username>/notebooks/に保存されます。
opcユーザーとして、JupyterHubがインストールされているユーティリティ・ノード(HA (高可用性)クラスタの2番目のユーティリティ・ノード、または非HAクラスタの最初で唯一のユーティリティ・ノード)に接続します。sudoを使用して、/opt/jupyterhub/jupyterhub_config.pyに格納されているJupyterHub構成を管理します。c.Spawner.args = ['--ServerApp.contents_manager_class="hdfscm.HDFSContentsManager"']sudoを使用して、JupyterHubを再起動します。sudo systemctl restart jupyterhub.service
管理者ユーザーは、個々のユーザー・ノートブックをHDFSではなくオブジェクト・ストレージに格納できます。コンテンツ・マネージャをHDFSからオブジェクト・ストレージに変更すると、既存のノートブックはオブジェクト・ストレージにコピーされません。新しいノートブックはオブジェクト・ストレージに保存されます。
opcユーザーとして、JupyterHubがインストールされているユーティリティ・ノード(HA (高可用性)クラスタの2番目のユーティリティ・ノード、または非HAクラスタの最初で唯一のユーティリティ・ノード)に接続します。sudoを使用して、/opt/jupyterhub/jupyterhub_config.pyに格納されているJupyterHub構成を管理します。必要なキーの生成方法を学習するには、アクセスおよび秘密キーの生成を参照してください。c.Spawner.args = ['--ServerApp.contents_manager_class="s3contents.S3ContentsManager"', '--S3ContentsManager.bucket="<bucket-name>"', '--S3ContentsManager.access_key_id="<accesskey>"', '--S3ContentsManager.secret_access_key="<secret-key>"', '--S3ContentsManager.endpoint_url="https://<object-storage-endpoint>"', '--S3ContentsManager.region_name="<region>"','--ServerApp.root_dir=""']sudoを使用して、JupyterHubを再起動します。sudo systemctl restart jupyterhub.service
オブジェクト・ストレージとの統合
ビッグ・データ・サービス・クラスタで使用するために、Sparkとオブジェクト・ストレージを統合します。
JupyterHubで、Sparkによってオブジェクト・ストレージを操作するには、いくつかのシステム・プロパティを定義し、それらをSpark構成のspark.driver.extraJavaOptionおよびspark.executor.extraJavaOptionsプロパティに移入する必要があります。
JupyterHubをオブジェクト・ストレージと正常に統合するには、次を実行する必要があります:
- オブジェクト・ストアにバケットを作成してデータを格納します。
- オブジェクト・ストレージAPIキーを作成します。
Spark構成で定義する必要があるプロパティは:
TenantIDUseridFingerprintPemFilePathPassPhraseRegion
これらのプロパティの値を取得するには:
- ナビゲーション・メニューを開き、「アナリティクスとAI」をクリックします。「データ・レイク」で、「ビッグ・データ・サービス」をクリックします。
- 「コンパートメント」で、クラスタをホストするコンパートメントを選択します。
- クラスタのリストで、JupyterHubを使用しているクラスタをクリックします。
- 「リソース」で、「オブジェクト・ストレージAPIキー」をクリックします。
- 表示するAPIキーの「アクション」メニューから、「構成ファイルの表示」をクリックします。
構成ファイルには、パスフレーズを除くすべてのシステム・プロパティの詳細が含まれます。オブジェクト・ストレージAPIキーの作成時にパスフレーズが指定されるため、同じパスフレーズを記憶して使用する必要があります。
- JupyterHubにアクセスします。
- 新しいノートブックを開きます。
- 次のコマンドをコピーして貼り付け、Sparkに接続します。
import findspark findspark.init() import pyspark - 次のコマンドをコピーして貼り付け、指定した構成でSparkセッションを作成します。以前に取得したシステム・プロパティ値を変数に置き換えます。
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("spark.driver.extraJavaOptions", "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .config("spark.executor.extraJavaOptions" , "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .appName("<appname>") \ .getOrCreate() - 次のコマンドをコピーして貼り付け、オブジェクト・ストレージ・ディレクトリおよびファイルを作成し、Parquet形式でデータを格納します。
demoUri = "oci://<BucketName>@<Tenancy>/<DirectoriesAndSubDirectories>/" parquetTableUri = demoUri + "<fileName>" spark.range(10).repartition(1).write.mode("overwrite").format("parquet").save(parquetTableUri) - 次のコマンドをコピーして貼り付け、オブジェクト・ストレージからデータを読み取ります。
spark.read.format("parquet").load(parquetTableUri).show() - これらのすべてのコマンドを使用してノートブックを実行します。
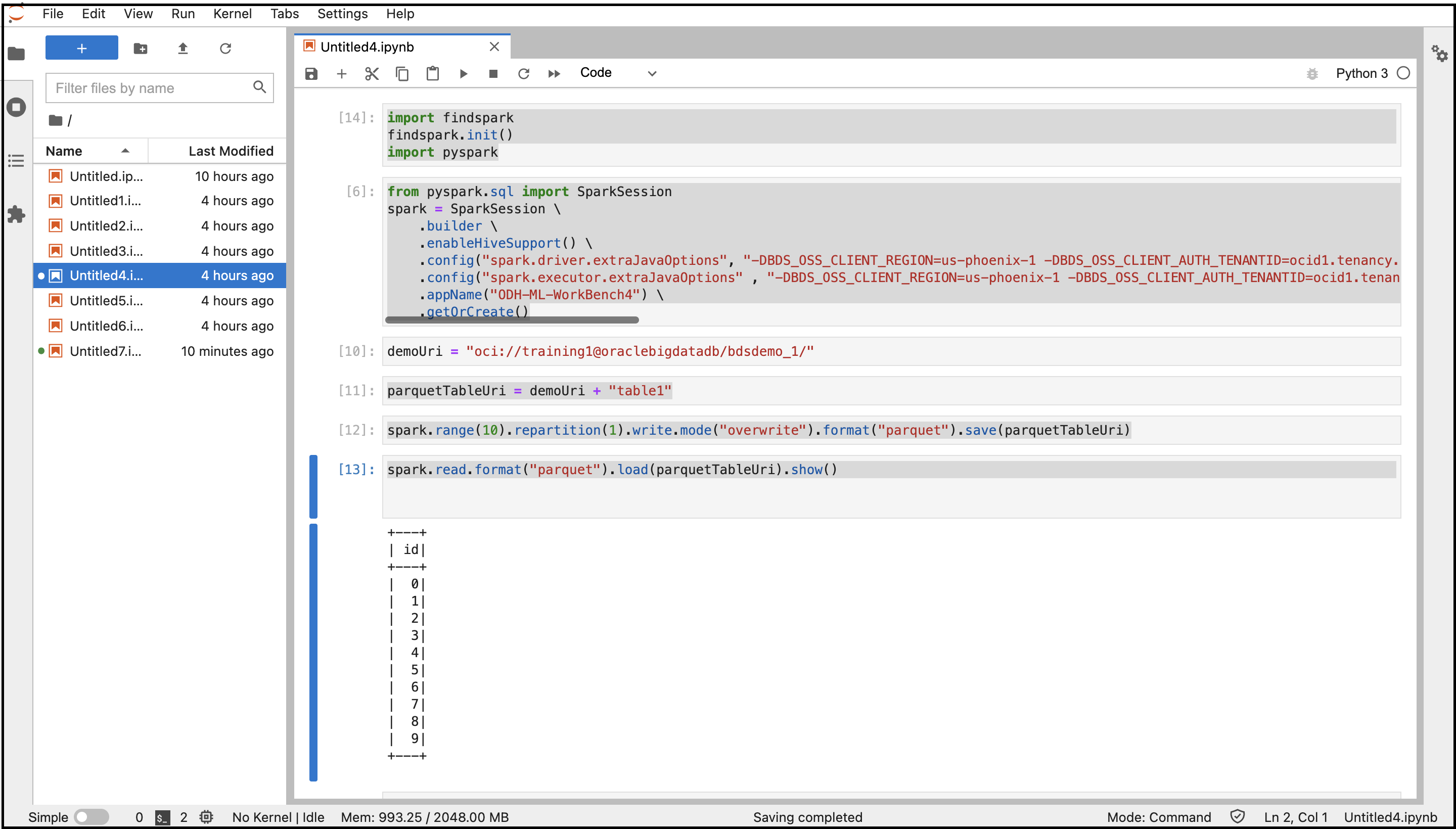
コードの出力が表示されます。コンソールからオブジェクト・ストレージ・バケットに移動し、バケットに作成されたファイルを検索できます。
ユーザーおよび権限の管理
ノートブックを作成し、オプションでJupyterHubを管理できるように、2つの認証メソッドのいずれかを使用してJupyterHubに対してユーザーを認証します。
デフォルトでは、ODH 1.xクラスタはネイティブ認証をサポートします。ただし、JupyterHubおよびその他のビッグ・データ・サービスの認証は、別の方法で処理する必要があります。JupyterHubにサインインするユーザーは、Linuxホストに存在し、HDFSのルート・ディレクトリに対する書込み権限を持っている必要があります。それ以外の場合、ノートブック・プロセスがLinuxユーザーとしてトリガーされると、生成は失敗します。
ネイティブ認証の詳細は、ネイティブ認証を参照してください。
ビッグ・データ・サービス3.0.26以前のLDAP認証の詳細は、LDAP認証を参照してください。
ネイティブ認証は、ユーザーを認証するためのJupyterHubユーザー・データベースによって異なります。
ネイティブ認証は、HAクラスタと非HAクラスタの両方に適用されます。ネイティブ・オーセンティケータの詳細は、ネイティブ・オーセンティケータを参照してください。
ネイティブ認証を使用してビッグ・データ・サービスHAクラスタのユーザーを認可するには、これらの前提条件が満たされている必要があります。
ネイティブ認証を使用してビッグ・データ・サービス非HAクラスタのユーザーを認可するには、これらの前提条件が満たされている必要があります。
管理者ユーザーは、JupyterHubの構成および管理について責任を負います。また、管理者ユーザーは、JupyterHubで新しくサインアップしたユーザーの認可も担当します。
- Apache Ambariにアクセスします。
- サイド・ツールバーの「Services」で、JupyterHubをクリックします。
- 「Configs」、「Advanced Configs」の順にクリックします。
- 「Advanced jupyterhub-config」を選択します。
-
c.Authenticator.admin_usersに管理ユーザーを追加します。 - 「保存」をクリックします
他のユーザーを追加する前に、ビッグ・データ・サービス・クラスタの前提条件を満たす必要があります。
-
管理ユーザーは、JupyterHubにサインインし、新しいメニュー・オプションからサインイン・ユーザーを認可する必要があります。
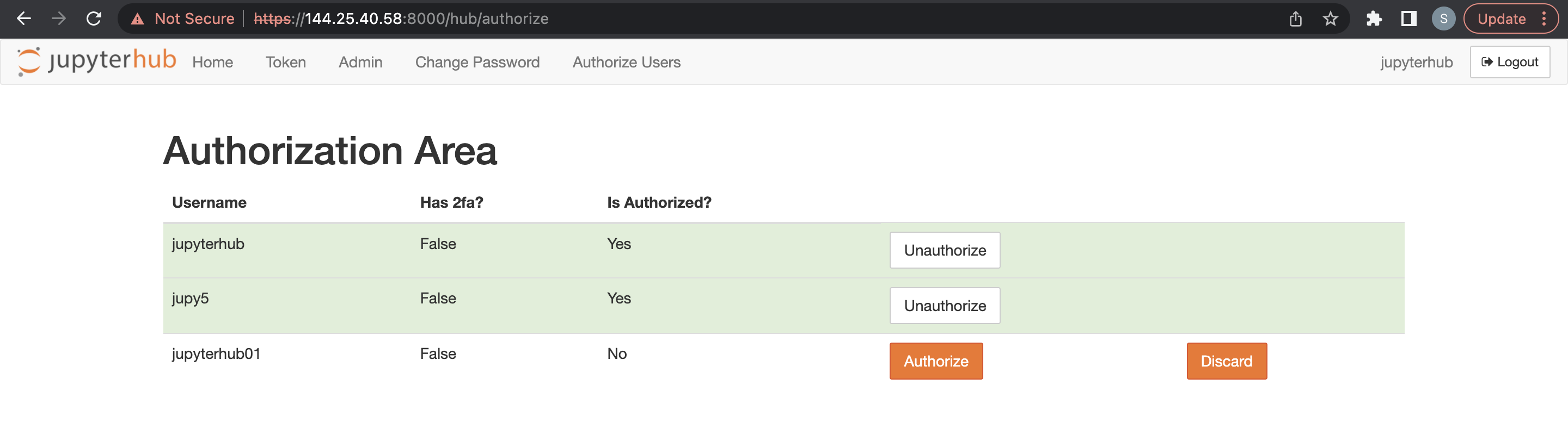
ビッグ・データ・サービス3.0.26以前のODH 1.xクラスタのブラウザを介してLDAP認証を使用できます。
Trinoとの統合
- Trinoは、ビッグ・データ・サービス・クラスタにインストールおよび構成されている必要があります。
- 次のPythonモジュールをJupyterHubノードにインストールします(HAの場合はun1、HA以外のクラスタの場合はun0) ノート
Trino-Pythonモジュールがすでにノードに存在する場合、このステップは無視してください。python3.6 -m pip install trino[sqlalchemy] Offline Installation: Download the required python module in any machine where we have internet access Example: python3 -m pip download trino[sqlalchemy] -d /tmp/package Copy the above folder content to the offline node & install the package python3 -m pip install ./package/* Note : trino.sqlalchemy is compatible with the latest 1.3.x and 1.4.x SQLAlchemy versions. BDS cluster node comes with python3.6 and SQLAlchemy-1.4.46 by default.
Trino-Ranger-Pluginが有効になっている場合は、提供されているkeytabユーザーをそれぞれのTrino Rangerポリシーに追加してください。TrinoとRangerの統合を参照してください。
デフォルトでは、Trinoは完全なKerberosプリンシパル名をユーザーとして使用します。したがって、trino-rangerポリシーを追加/更新する場合は、ユーザー名として完全なKerberosプリンシパル名を使用する必要があります。
次のコード・サンプルでは、trino-rangerポリシーのユーザーとしてjupyterhub@BDSCLOUDSERVICE.ORACLE.COMを使用します。
Trino-Ranger-Pluginが有効になっている場合は、指定されたkeytabユーザーをそれぞれのTrino Rangerポリシーに追加してください。詳細は、「TrinoでのRangerの有効化」を参照してください。
JupyterHubのRanger権限を次のポリシーに提供します。
all - catalog, schema, table, columnall - function