ビッグ・データ・サービス3.0.27以降でのJupyterHubの使用
JupyterHubを使用して、ユーザーのグループのビッグ・データ・サービス3.0.27以降のODH 2.xノートブックを管理します。
前提条件
JupyterHubへのアクセス
- Apache Ambariにアクセスします。
- サイド・ツールバーの「Services」で、JupyterHubをクリックします。
ノートブックの生成
ビッグ・データ・サービス3.0.27以降のODH 2.xクラスタでは、次のSpawner構成がサポートされています。
次を完了します:
- システムネイティブ認証:
- サインインしたユーザー資格証明を使用してサインインします。
- ユーザー名を入力します
- パスワードの入力
- SamlSSOAuthenticatorの使用:
- SSOサイン・インでサイン・インします。
- 構成されたSSOアプリケーションでサインインを完了します。
HAクラスタでのノートブックの生成
AD統合クラスタの場合:
- 前述のいずれかの方法を使用してサインインします。この認可は、ユーザーがLinuxホストに存在する場合にのみ機能します。JupyterHubは、ノートブック・サーバーの起動の試行中にLinuxホストでユーザーを検索します。
- 「サーバー・オプション」ページにリダイレクトされ、Kerberosチケットをリクエストする必要があります。このチケットは、Kerberosプリンシパルとkeytabファイル、またはKerberosパスワードを使用してリクエストできます。クラスタ管理者は、Kerberosプリンシパルとkeytabファイル、またはKerberosパスワードを提供できます。Kerberosチケットは、使用するHDFSディレクトリおよびその他のビッグ・データ・サービスにアクセスする必要があります。
非HAクラスタでのノートブックの生成
AD統合クラスタの場合:
前述のいずれかの方法を使用してサインインします。この認可は、ユーザーがLinuxホストに存在する場合にのみ機能します。JupyterHubは、ノートブック・サーバーの起動の試行中にLinuxホストでユーザーを検索します。
JupyterHubの管理
JupyterHub adminユーザーは、次のタスクを実行して、ビッグ・データ・サービス3.0.27以降のODH 2.xノードでJupyterHubのノートブックを管理できます。
systemctlコマンドを使用してOracle Linux 7サービスを管理するには、システム・サービスの作業を参照してください。
Oracle Cloud Infrastructureインスタンスにサインインするには、インスタンスへの接続を参照してください。
管理者は、JupyterHubを停止または無効化して、メモリーなどのリソースを消費しないようにできます。予期しない問題や動作が発生した場合は、再起動すると解決することがあります。
Ambari for Big Data Service 3.0.27以降のクラスタでJupyterHubを停止または起動します。
管理者は、JupyterHubサーバーをビッグ・データ・サービス・ノードに追加できます。
これは、Big Data Service 3.0.27以降のクラスタで使用できます。
- Apache Ambariにアクセスします。
- サイド・ツールバーで、「ホスト」をクリックします。
- JupyterHubサーバーを追加するには、JupyterHubがインストールされていないホストを選択します。
- 「追加」をクリックします。
- JupyterHubサーバーを選択します。
管理者は、JupyterHubサーバーを別のビッグ・データ・サービス・ノードに移動できます。
これは、Big Data Service 3.0.27以降のクラスタで使用できます。
- Apache Ambariにアクセスします。
- サイド・ツールバーの「Services」で、JupyterHubをクリックします。
- 「アクション」、「JupyterHubサーバーの移動」の順にクリックします。
- 「次へ」をクリックします。
- JupyterHubサーバーの移動先のホストを選択します。
- 移動ウィザードを完了します。
管理者は、Ambariを介してJupyterHubサービス/ヘルス・チェックを実行できます。
これは、Big Data Service 3.0.27以降のクラスタで使用できます。
- Apache Ambariにアクセスします。
- サイド・ツールバーの「Services」で、JupyterHubをクリックします。
- 「処理」、「サービス・チェックの実行」の順にクリックします。
ユーザーおよび権限の管理
ノートブックを作成し、オプションでビッグ・データ・サービス3.0.27以降のODH 2.xクラスタでJupyterHubを管理できるように、2つの認証メソッドのいずれかを使用してJupyterHubに対してユーザーを認証します。
JupyterHubユーザーは、Active Directory (AD)以外のビッグ・データ・サービス・クラスタのすべてのビッグ・データ・サービス・クラスタ・ノードでOSユーザーとして追加する必要があります。この場合、ユーザーはすべてのクラスタ・ノード間で自動的に同期されません。管理者は、JupyterHubにサインインする前に、JupyterHubユーザー管理スクリプトを使用してユーザーおよびグループを追加できます。
前提条件
JupyterHubにアクセスする前に、次のことを完了します。
- JupyterHubがインストールされているノードにSSHサインインします。
/usr/odh/current/jupyterhub/installにナビゲートします。sample_user_groups.jsonファイル内のすべてのユーザーおよびグループの詳細を指定するには、次を実行します:sudo python3 UserGroupManager.py sample_user_groups.json Verify user creation by executing the following command: id <any-user-name>
サポートされる認証タイプ
- NativeAuthenticator: このオーセンティケータは、小規模または中規模のJupyterHubアプリケーションに使用されます。サインアップおよび認証は、外部サービスに依存することなく、JupyterHubにネイティブとして実装されます。
- SSOAuthenticator: このオーセンティケータは、SAML2サービス・プロバイダとして機能する
jupyterhub.auth.Authenticatorのサブクラスを提供します。適切に構成されたSAML2アイデンティティ・プロバイダに移動し、JupyterHubのシングル・サインオンを有効にします。
ネイティブ認証は、ユーザーを認証するためのJupyterHubユーザー・データベースによって異なります。
ネイティブ認証は、HAクラスタと非HAクラスタの両方に適用されます。ネイティブ・オーセンティケータの詳細は、ネイティブ・オーセンティケータを参照してください。
ネイティブ認証を使用してビッグ・データ・サービスHAクラスタのユーザーを認可するには、これらの前提条件が満たされている必要があります。
ネイティブ認証を使用してビッグ・データ・サービス非HAクラスタのユーザーを認可するには、これらの前提条件が満たされている必要があります。
管理者ユーザーは、JupyterHubの構成および管理について責任を負います。また、管理者ユーザーは、JupyterHubで新しくサインアップしたユーザーの認可も担当します。
- Apache Ambariにアクセスします。
- サイド・ツールバーの「Services」で、JupyterHubをクリックします。
- 「Configs」、「Advanced Configs」の順にクリックします。
- 「Advanced jupyterhub-config」を選択します。
-
c.Authenticator.admin_usersに管理ユーザーを追加します。 - 「保存」をクリックします
他のユーザーを追加する前に、ビッグ・データ・サービス・クラスタの前提条件を満たす必要があります。
-
管理ユーザーは、JupyterHubにサインインし、新しいメニュー・オプションからサインイン・ユーザーを認可する必要があります。
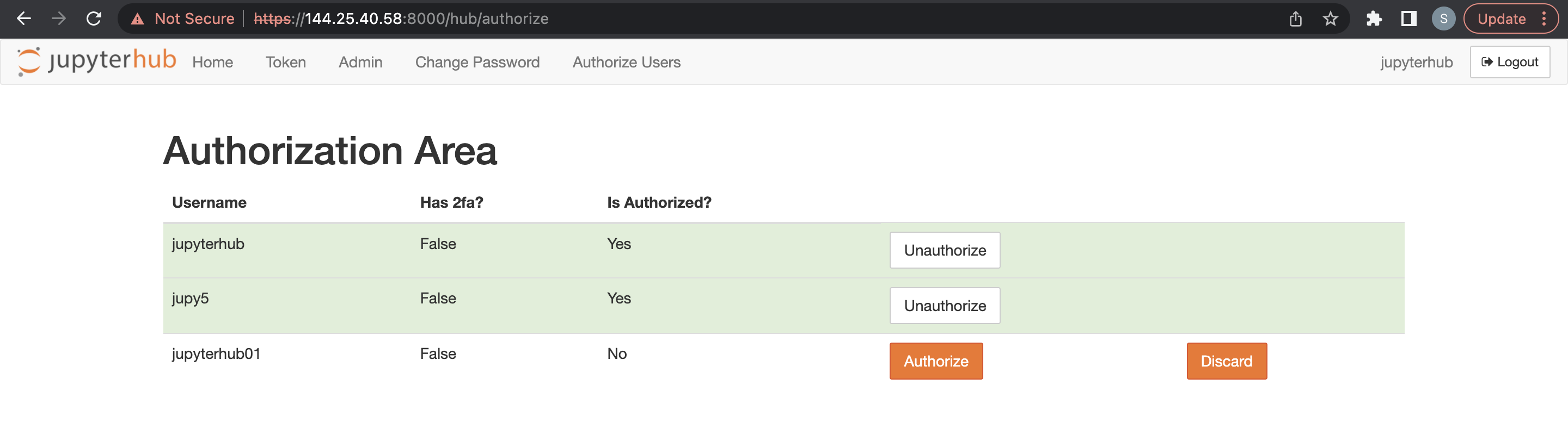
Ambari for Big Data Service 3.0.27以降のODH 2.xクラスタを介してLDAP認証を使用できます。
Ambariを使用したLDAP認証の使用
LDAP認証プロバイダを使用するには、LDAP接続の詳細でJupyterHub構成ファイルを更新する必要があります。
Big Data Service 3.0.27以降のクラスタでLDAP認証にAmbariを使用します。
LDAPオーセンティケータの詳細は、LDAPオーセンティケータを参照してください。
ビッグ・データ・サービス3.0.27以降のODH 2.x JupyterHubサービスのpConfigure SSO認証。
Oracle Identity Domainを使用して、ビッグ・データ・サービス3.0.27以降のODH 2.x JupyterHubクラスタでSSO認証を設定できます。
OKTAを使用して、ビッグ・データ・サービス3.0.27以降のODH 2.x JupyterHubクラスタでSSO認証を設定できます。
管理者は、Ambari for Big Data Service 3.0.27以降のODH 2.xクラスタを介してJupyterHub構成を管理できます。
ノートブックの生成
ビッグ・データ・サービス3.0.27以降のODH 2.xクラスタでは、次のSpawner構成がサポートされています。
次を完了します:
- システムネイティブ認証:
- サインインしたユーザー資格証明を使用してサインインします。
- ユーザー名を入力します
- パスワードの入力
- SamlSSOAuthenticatorの使用:
- SSOサイン・インでサイン・インします。
- 構成されたSSOアプリケーションでサインインを完了します。
HAクラスタでのノートブックの生成
AD統合クラスタの場合:
- 前述のいずれかの方法を使用してサインインします。この認可は、ユーザーがLinuxホストに存在する場合にのみ機能します。JupyterHubは、ノートブック・サーバーの起動の試行中にLinuxホストでユーザーを検索します。
- 「サーバー・オプション」ページにリダイレクトされ、Kerberosチケットをリクエストする必要があります。このチケットは、Kerberosプリンシパルとkeytabファイル、またはKerberosパスワードを使用してリクエストできます。クラスタ管理者は、Kerberosプリンシパルとkeytabファイル、またはKerberosパスワードを提供できます。Kerberosチケットは、使用するHDFSディレクトリおよびその他のビッグ・データ・サービスにアクセスする必要があります。
非HAクラスタでのノートブックの生成
AD統合クラスタの場合:
前述のいずれかの方法を使用してサインインします。この認可は、ユーザーがLinuxホストに存在する場合にのみ機能します。JupyterHubは、ノートブック・サーバーの起動の試行中にLinuxホストでユーザーを検索します。
- ビッグ・データ・サービス・クラスタ・ノードのSSHキー/アクセス・トークンを構成します。
- ノートブック永続性モードをGitとして選択します。
JupyterHubのGit接続を設定するには、次の手順を実行します。
- ビッグ・データ・サービス・クラスタ・ノードのSSHキーの構成/アクセス・トークン。
- ノートブック永続性モードをGitとして選択します
SSHキー・ペアの生成
アクセス・トークンの使用
次の方法でアクセス・トークンを使用できます。
- GitHub:
- GitHubアカウントにサインインします。
- 「設定」→「開発者設定」→「個人アクセス・トークン」にナビゲートします。
- 適切な権限を持つ新しいアクセス・トークンを生成します。
- 認証を求められたら、アクセス・トークンをパスワードとして使用します。
- GitLab:
- GitHubアカウントにサインインします。
- 「設定」→「アクセス・トークン」にナビゲートします。
- 適切な権限を持つ新しいアクセス・トークンを生成します。
- 認証を求められたら、アクセス・トークンをパスワードとして使用します。
- BitBucket:
- BitBucketアカウントにサインインします。
- 「設定」→「アプリケーション・パスワード」にナビゲートします。
- 適切な権限を持つ新しいアプリケーション・パスワード・トークンを生成します。
- 認証を求められたら、新しいアプリケーション・パスワードをパスワードとして使用します。
Gitでの永続性モードの選択
- Apache Ambariにアクセスします。
- サイド・ツールバーの「Services」で、JupyterHubをクリックします。
- 「Configs」、「Settings」の順にクリックします。
- ノートブック永続性モードを検索し、ドロップダウンから「Git」を選択します。
- 「アクション」、「すべて再起動」の順にクリックします。
- Apache Ambariにアクセスします。
- サイド・ツールバーの「Services」で、JupyterHubをクリックします。
- 「Configs」、「Settings」の順にクリックします。
- ノートブック永続性モードを検索し、ドロップダウンから「HDFS」を選択します。
- 「アクション」、「すべて再起動」の順にクリックします。
管理者ユーザーは、個々のユーザー・ノートブックをHDFSではなくオブジェクト・ストレージに格納できます。コンテンツ・マネージャをHDFSからオブジェクト・ストレージに変更すると、既存のノートブックはオブジェクト・ストレージにコピーされません。新しいノートブックはオブジェクト・ストレージに保存されます。
rcloneとユーザー・プリンシパル認証を使用したOracle Object Storageバケットのマウント
JupyterHubユーザーに合せて調整されたrcloneおよびfuse3を使用して、rcloneとユーザー・プリンシパル認証(APIキー)をビッグ・データ・サービス・クラスタ・ノードで使用してOracle Object Storageをマウントできます。
JupyterHubでのConda環境の管理
Big Data Service 3.0.28以降のODH 2.xクラスタでConda環境を管理できます。
- 特定の依存関係を持つconda環境を作成し、作成されたconda環境を指す4つのカーネル(Python/PySpark/Spark/SparkR)を作成します。
- この操作を使用して作成されたConda環境およびカーネルは、すべてのノートブック・サーバー・ユーザーが使用できます。
- 個別のconda環境作成操作は、サービスの再起動で操作を切り離すことです。
- JupyterHubは、Ambari UIを介してインストールされます。
- クラスタへのインターネット・アクセスを検証して、condaの作成中に依存関係をダウンロードします。
- この操作を使用して作成されたConda環境およびカーネルは、すべてのノートブック・サーバー・ユーザーが使用できます。」
- 指定:
- conda作成の失敗を回避するためのConda追加構成。詳細は、conda createを参照してください。
- 標準要件
.txt形式の依存性。 - 存在しないconda環境名。
- conda envsまたはカーネルを手動で削除します。
この操作により、指定された依存関係を持つconda環境が作成され、作成されたconda環境を指す指定されたカーネル(Python/PySpark/Spark/SparkR)が作成されます。
- 指定されたconda環境がすでに存在する場合、操作は直接カーネル作成ステップに進みます
- この操作を使用して作成されたConda環境またはカーネルは、特定のユーザーのみが使用できます
- sudoモードでpythonスクリプト
kernel_install_script.pyを手動で実行します。'/var/lib/ambari-server/resources/mpacks/odh-ambari-mpack-2.0.8/stacks/ODH/1.1.12/services/JUPYTER/package/scripts/'例:
sudo python kernel_install_script.py --conda_env_name conda_jupy_env_1 --conda_additional_configs '--override-channels --no-default-packages --no-pin -c pytorch' --custom_requirements_txt_file_path ./req.txt --kernel_type spark --kernel_name spark_jupyterhub_1 --user jupyterhub
前提条件
- クラスタへのインターネット・アクセスを検証して、condaの作成中に依存関係をダウンロードします。そうしないと、作成が失敗します。
--kernel_nameという名前のカーネルが存在する場合、例外がスローされます。- 次の情報が提供されます。
- 作成の失敗を回避するためのConda構成。詳細は、https://conda.io/projects/conda/en/latest/commands/create.htmlを参照してください。
- 標準要件
.txt形式で提供される依存性。
- 任意のユーザーのconda列挙またはカーネルを手動で削除します。
カスタマイズに使用可能な構成
--user(必須): カーネルおよびconda環境が作成されるOSおよびJupyterHubユーザー。--conda_env_name(必須):--userに対して新しいenが作成されるたびに、conda環境に一意の名前を指定します。--kernel_name: (必須)一意のカーネル名を指定します。--kernel_type: (必須)次のいずれかである必要があります(python / PysPark / Spark / SparkR)--custom_requirements_txt_file_path: (オプション)いずれかのPython/R/Ruby/Lua/Scala/Java/JavaScript/C/C++/FORTRANなどで、condaチャネルを使用して依存関係がインストールされている場合は、要件の.txtファイルにそれらのライブラリを指定し、フルパスを指定する必要があります。要件
.txtファイルを定義するための標準フォーマットの詳細は、https://pip.pypa.io/en/stable/reference/requirements-file-format/を参照してください。--conda_additional_configs: (オプション)- このフィールドには、デフォルトのconda作成コマンドに追加する追加パラメータが表示されます。
- デフォルトのconda作成コマンドは
'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8'です。 --conda_additional_configsが'--override-channels --no-default-packages --no-pin -c pytorch'として指定されている場合、最終的なconda作成コマンドの実行は'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8 --override-channels --no-default-packages --no-pin -c pytorch'です。
ユーザー固有のConda環境の設定
Load Balancerおよびバックエンド・セットの作成
バックエンド・セットの作成の詳細は、Load Balancerバックエンド・セットの作成を参照してください。
パブリックLoad Balancerの作成の詳細は、Load Balancerの作成を参照し、次の詳細を入力します。
パブリックLoad Balancerの作成の詳細は、Load Balancerの作成を参照し、次の詳細を入力します。
- ナビゲーション・メニューを開き、「ネットワーキング」をクリックして、「ロード・バランサ」をクリックします。「ロード・バランサ」をクリックします。「ロード・バランサ」ページが表示されます。
- リストからコンパートメントを選択します。そのコンパートメント内のすべてのロード・バランサが表形式でリストされます。
- バックエンドを追加するロード・バランサをクリックします。ロード・バランサの詳細ページが表示されます。
- 「バックエンド・セット」を選択し、「Load Balancerの作成」で作成したバックエンド・セットを選択します。
- IPアドレスを選択し、クラスタの必要なプライベートIPアドレスを入力します。
- 「ポート」に8000と入力します。
- 「追加」をクリックします。
パブリックLoad Balancerの作成の詳細は、Load Balancerの作成を参照し、次の詳細を入力します。
-
ブラウザを開き、
https://<loadbalancer ip>:8000と入力します。 - リストからコンパートメントを選択します。そのコンパートメント内のすべてのロード・バランサが表形式でリストされます。
- JupyterHubサーバーのいずれかにリダイレクトされることを確認してください。確認するには、JupyterHubでターミナル・セッションを開いて、到達したノードを見つけます。
- ノードの追加操作の後、クラスタ管理者は、新しく追加されたノードのLoad Balancerホスト・エントリを手動で更新する必要があります。クラスタへのすべてのノード追加に適用できます。たとえば、ワーカー・ノード、コンピュートのみおよびノードです。
- 証明書の有効期限が切れた場合は、手動でLoad Balancerに更新する必要があります。このステップにより、Load Balancerで古い証明書が使用されていないことが保証され、バックエンド・セットに対するヘルス・チェック/通信の失敗が回避されます。詳細は、「期限切れが近いLoad Balancer証明書の更新」を参照して、期限切れの証明書を更新します。
Trino-SQLカーネルの起動
JupyterHub PyTrinoカーネルは、JupySQLを使用してTrino問合せを実行できるSQLインタフェースを提供します。これは、ビッグ・データ・サービス3.0.28以降のODH 2.xクラスタで使用できます。
SqlMagicパラメータの詳細は、https://jupysql.ploomber.io/en/latest/api/configuration.html#changing-configurationを参照してください。