ローカルでのOracle Cloud Infrastructureデータ・フロー・アプリケーションの開発、クラウドへのデプロイ
Oracle Cloud Infrastructureデータ・フローは、完全に管理されたApache Sparkクラウド・サービスです。これにより、Sparkアプリケーションをあらゆる規模で、最小限の管理または設定作業で実行できます。データ・フローは、信頼性のある長時間実行バッチ処理ジョブのスケジュールに最適です。
Sparkアプリケーションは、クラウドに接続せずに開発できます。ラップトップ・コンピュータでは、これらを迅速に開発、テストおよび反復できます。準備ができたら、再構成、コード変更またはデプロイメント・プロファイルの適用を行うことなく、データ・フローにデプロイできます。
- データ・フローの実行に使用されるソース・コードおよびライブラリのほとんどは非表示です。データ・フローSDKのバージョンと一致させる必要はなく、サードパーティの依存関係とデータ・フローが競合することもなくなります。
- SDKはSparkと互換性があるため、競合するサードパーティの依存関係を移動する必要がなくなり、アプリケーションをライブラリから分離して、より速く、複雑で、小さく、より柔軟なビルドを実現します。
- 新しいテンプレートであるpom.xmlファイルでは、ご使用のローカル・マシンに、データ・フローとほぼ同一のコピーがダウンロードされて構築されます。ローカル・マシンでステップ・デバッガを実行して、データ・フローでアプリケーションを実行する前に、問題を検出して解決できます。データ・フローが実行するライブラリとまったく同じバージョンのライブラリをコンパイルして実行できます。Oracleでは、問題がデータ・フローにあるか、アプリケーション・コードにあるかを迅速に判断できます。
開始する前に
アプリケーションの開発を始める前に、次の設定と作業が必要です:
- APIキー機能を有効にしたOracle Cloudログイン。 「アイデンティティ」 /「ユーザー」の下にユーザーをロードし、APIキーを作成できることを確認します。
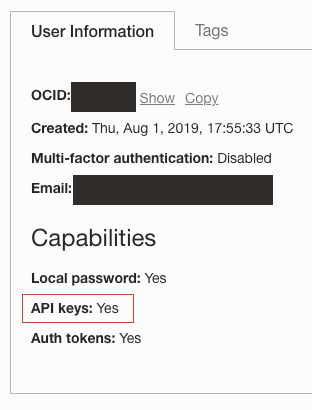
- ローカル環境に登録およびデプロイされているAPIキー。詳細は、APIキーの登録を参照してください。
- Apache Spark 2.4、3.0.2、3.2.1または3.5.0の動作するローカル・インストール。これを確認するには、CLIでspark-shellを実行します。
- インストールされたApache Maven。手順と例では、Mavenを使用して必要な依存関係をダウンロードします。
開始する前に、データ・フローでの実行のセキュリティを確認します。委任トークンを使用して、ユーザーにかわってクラウド操作を行うことができます。アカウントがOracle Cloud Infrastructure Consoleで実行できる操作は、Sparkジョブがデータ・フローを使用して実行できます。ローカル・モードで実行する場合は、ローカル・アプリケーションが様々なOracle Cloud Infrastructureサービスに対して認証済リクエストを実行できるようにするAPIキーを使用する必要があります。
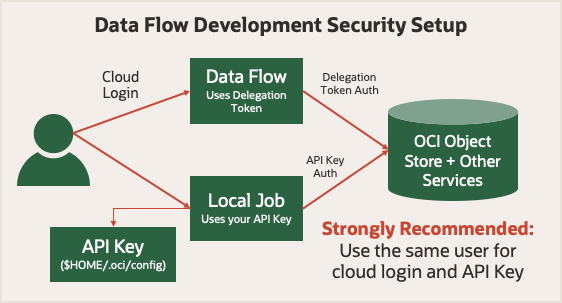
簡単にするには、Oracle Cloud Infrastructure Consoleへのログイン時と同じユーザーに対して生成されたAPIキーを使用します。つまり、アプリケーションは、ローカルで実行するかデータ・フローで実行するかに関係なく、同じ権限を持ちます。
1. ローカル開発の概念
- Oracle Cloud Infrastructureライブラリ・ファイルを使用して、データ・フローのランタイム環境に似るようにローカルSparkインストールをカスタマイズします。
- コードが実行されている場所を検出します。
- Oracle Cloud Infrastructure HDFSクライアントを適切に構成します。
コンピュータとデータ・フロー間をシームレスに移動できるように、ローカル設定で特定のバージョンのSpark、ScalaおよびPythonを使用する必要があります。Oracle Cloud Infrastructure HDFS Connector JARファイルを追加します。また、アプリケーションがデータ・フローで実行されるときにインストールされる10個の依存関係ライブラリをSparkインストールに追加します。次のステップでは、これらの10個の依存関係ライブラリをダウンロードしてインストールする方法を示します。
| Sparkバージョン | Scalaバージョン | Pythonバージョン |
|---|---|---|
| 3.5.0 | 2.12.18 | 3.11.5 |
| 3.2.1 | 2.12.15 | 3.8 |
| 3.0.2 | 2.12.10 | 3.6.8 |
| 2.4.4 | 2.11.12 | 3.6.8 |
CONNECTOR=com.oracle.oci.sdk:oci-hdfs-connector:3.3.4.1.4.2
mkdir -p deps
touch emptyfile
mvn install:install-file -DgroupId=org.projectlombok -DartifactId=lombok -Dversion=1.18.26 -Dpackaging=jar -Dfile=emptyfile
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps -Dtransitive=true -Dpackaging=pom
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:copy-dependencies -f deps/*.pom -DoutputDirectory=.echo 'sc.getConf.get("spark.home")' | spark-shellscala> sc.getConf.get("spark.home")
res0: String = /usr/local/lib/python3.11/site-packages/pyspark/usr/local/lib/python3.11/site-packages/pyspark/jarsdepsディレクトリには多数のJARファイルが含まれ、そのほとんどはSparkインストールですでに使用可能になっています。次のJARファイルのサブセットのみをSpark環境にコピーする必要があります:bcpkix-jdk15to18-1.74.jar
bcprov-jdk15to18-1.74.jar
guava-32.0.1-jre.jar
jersey-media-json-jackson-2.35.jar
oci-hdfs-connector-3.3.4.1.4.2.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
oci-java-sdk-common-*.jar
oci-java-sdk-objectstorage-extensions-3.34.0.jar
jersey-apache-connector-2.35.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
jersey-media-json-jackson-2.35.jar
oci-java-sdk-objectstorage-generated-3.34.0.jar
oci-java-sdk-circuitbreaker-3.34.0.jar
resilience4j-circuitbreaker-1.7.1.jar
resilience4j-core-1.7.1.jar
vavr-match-0.10.2.jar
vavr-0.10.2.jardepsディレクトリからステップ2で見つけたjarsサブディレクトリにコピーします。import com.oracle.bmc.hdfs.BmcFilesystem正しくデプロイされたJARファイル 
エラーがある場合は、ファイルを誤った場所に配置しました。この例では、エラーがあります:
間違ってデプロイされたJARファイル 
SparkConfオブジェクトでspark.masterの値を使用できます。この値は、データ・フローでの実行時にk8s://https://kubernetes.default.svc:443に設定されます。- データ・フローで実行する場合、
HOME環境変数は/home/dataflowに設定されます。
PySparkアプリケーションでは、新しく作成されたSparkConfオブジェクトは空です。正しい値を表示するには、実行中のSparkContextのgetConfメソッドを使用します。
| 起動環境 | spark.master設定 |
|---|---|
| データ・フロー | |
| ローカルspark-submit | spark.master: local[*] $HOME: 変数 |
| Eclipse | 設定解除 $HOME: 変数 |
データ・フローで実行している場合は、
spark.masterの値を変更しないでください。これを行うと、プロビジョニングしたすべてのリソースがジョブで使用されません。 アプリケーションがデータ・フローで実行されると、Oracle Cloud Infrastructure HDFS Connectorが自動的に構成されます。ローカルで実行する場合は、HDFSコネクタ構成プロパティを設定して自分で構成する必要があります。
少なくとも、SparkConfオブジェクトを更新して、fs.oci.client.auth.fingerprint、fs.oci.client.auth.pemfilepath、fs.oci.client.auth.tenantId、fs.oci.client.auth.userIdおよびfs.oci.client.hostnameの値を設定する必要があります。
APIキーにパスフレーズがある場合は、fs.oci.client.auth.passphraseを設定する必要があります。
これらの変数は、セッションの作成後に設定できます。プログラミング環境内で、それぞれのSDKを使用してAPIキー構成を正しくロードします。
ConfigFileAuthenticationDetailsProviderのパスまたはプロファイル引数を置き換えます:import com.oracle.bmc.auth.ConfigFileAuthenticationDetailsProvider;
import com.oracle.bmc.ConfigFileReader;
//If your key is encrypted call setPassPhrase:
ConfigFileAuthenticationDetailsProvider authenticationDetailsProvider = new ConfigFileAuthenticationDetailsProvider(ConfigFileReader.DEFAULT_FILE_PATH, "<DEFAULT>");
configuration.put("fs.oci.client.auth.tenantId", authenticationDetailsProvider.getTenantId());
configuration.put("fs.oci.client.auth.userId", authenticationDetailsProvider.getUserId());
configuration.put("fs.oci.client.auth.fingerprint", authenticationDetailsProvider.getFingerprint());
String guessedPath = new File(configurationFilePath).getParent() + File.separator + "oci_api_key.pem";
configuration.put("fs.oci.client.auth.pemfilepath", guessedPath);
// Set the storage endpoint:
String region = authenticationDetailsProvider.getRegion().getRegionId();
String hostName = MessageFormat.format("https://objectstorage.{0}.oraclecloud.com", new Object[] { region });
configuration.put("fs.oci.client.hostname", hostName);oci.config.from_fileのパスまたはプロファイル引数を置き換えます:import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# Check to see if we're in Data Flow or not.
if os.environ.get("HOME") == "/home/dataflow":
spark_session = SparkSession.builder.appName("app").getOrCreate()
else:
conf = SparkConf()
oci_config = oci.config.from_file(oci.config.DEFAULT_LOCATION, "<DEFAULT>")
conf.set("fs.oci.client.auth.tenantId", oci_config["tenancy"])
conf.set("fs.oci.client.auth.userId", oci_config["user"])
conf.set("fs.oci.client.auth.fingerprint", oci_config["fingerprint"])
conf.set("fs.oci.client.auth.pemfilepath", oci_config["key_file"])
conf.set(
"fs.oci.client.hostname",
"https://objectstorage.{0}.oraclecloud.com".format(oci_config["region"]),
)
spark_builder = SparkSession.builder.appName("app")
spark_builder.config(conf=conf)
spark_session = spark_builder.getOrCreate()
spark_context = spark_session.sparkContext
SparkSQLでは、構成は異なる方法で管理されます。これらの設定は--hiveconfスイッチを使用して渡されます。Spark SQL問合せを実行するには、例のようなラッパー・スクリプトを使用します。データ・フローでスクリプトを実行すると、これらの設定が自動的に行われます。
#!/bin/sh
CONFIG=$HOME/.oci/config
USER=$(egrep ' user' $CONFIG | cut -f2 -d=)
FINGERPRINT=$(egrep ' fingerprint' $CONFIG | cut -f2 -d=)
KEYFILE=$(egrep ' key_file' $CONFIG | cut -f2 -d=)
TENANCY=$(egrep ' tenancy' $CONFIG | cut -f2 -d=)
REGION=$(egrep ' region' $CONFIG | cut -f2 -d=)
REMOTEHOST="https://objectstorage.$REGION.oraclecloud.com"
spark-sql \
--hiveconf fs.oci.client.auth.tenantId=$TENANCY \
--hiveconf fs.oci.client.auth.userId=$USER \
--hiveconf fs.oci.client.auth.fingerprint=$FINGERPRINT \
--hiveconf fs.oci.client.auth.pemfilepath=$KEYFILE \
--hiveconf fs.oci.client.hostname=$REMOTEHOST \
-f script.sql
前述の例では、Spark Contextの構築方法のみが変更されます。Sparkアプリケーションの他に変更が必要なものはないため、Sparkアプリケーションの他の側面を通常どおりに開発できます。Sparkアプリケーションをデータ・フローにデプロイする場合、コードや構成を変更する必要はありません。
2. Javaアプリケーション用の"Fat JAR"の作成
JavaおよびScalaアプリケーションでは、通常、"Fat JAR"と呼ばれるJARファイルに依存関係をさらに含める必要があります。
Mavenを使用する場合は、Shadeプラグインを使用してこれを実行できます。次の例は、Maven pom.xmlファイルのものです。お客様のプロジェクトの開始点として使用できます。アプリケーションをビルドすると、依存関係が自動的にダウンロードされ、ランタイム環境に挿入されます。
Spark 3.5.0または3.2.1を使用している場合、この章は適用されません。かわりに、「2. データ・フローでのApache SparkアプリケーションのJava依存関係の管理」に従ってください。
pom.xmlのこの部分には、データ・フロー(Spark 3.0.2)に適切なSparkおよびOracle Cloud Infrastructureのライブラリ・バージョンが記述されています。Java 8をターゲットにし、共通の競合するクラス・ファイルをシェーディングします。
<properties>
<oci-java-sdk-version>1.25.2</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>3.2.1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>このpom.xml部分には、データ・フロー(Spark 2.4.4)の適切なSparkおよびOracle Cloud Infrastructureライブラリ・バージョンが含まれています。Java 8をターゲットにし、共通の競合するクラス・ファイルをシェーディングします。
<properties>
<oci-java-sdk-version>1.15.4</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>2.7.7.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>3. ローカルでのアプリケーションのテスト
アプリケーションをデプロイする前に、ローカルでテストして動作することを確認できます。使用できる3つの手法を選択します。これらの例では、アプリケーション・アーティファクトの名前がapplication.jar (Javaの場合)またはapplication.py (Pythonの場合)であると想定しています。
- データ・フローでは、実行に使用するソース・コードおよびライブラリのほとんどが非表示になるため、データ・フローSDKのバージョンは一致する必要がなくなり、データ・フローとのサード・パーティ依存関係の競合が発生しないようにする必要があります。
- Sparkは、OCI SDKとの互換性が確保されるようにアップグレードされました。つまり、競合するサードパーティの依存関係は移動する必要がないため、アプリケーションとライブラリのライブラリを分離して、より高速で、より複雑で、より小さく、より柔軟なビルドを実現できます。
- 新しいテンプレートのpom.xmlファイルでは、開発者のローカル・マシンに、データ・フローのほぼ同一のコピーがダウンロードおよび構築されます。つまり:
- 開発者は、ローカル・マシンでステップ・デバッガを実行して、データ・フローで実行する前に問題をすばやく検出して解決できます。
- 開発者は、データ・フローが実行するライブラリとまったく同じバージョンのライブラリをコンパイルして実行できます。そのため、データ・フロー・チームは、問題がデータ・フローまたはアプリケーション・コードの問題であるかどうかを迅速に判断できます。
方法1: IDEからの実行
EclipseなどのIDEで開発した場合は、「Run」をクリックして適切なメイン・クラスを選択する以外に何もする必要はありません。 
実行すると、Sparkによってコンソールに警告メッセージが生成され、Sparkが起動中であることがわかります。 
方法2: コマンドラインからのPySparkの実行
python3 application.py$ python3 example.py
Warning: Ignoring non-Spark config property: fs.oci.client.hostname
Warning: Ignoring non-Spark config property: fs.oci.client.auth.fingerprint
Warning: Ignoring non-Spark config property: fs.oci.client.auth.tenantId
Warning: Ignoring non-Spark config property: fs.oci.client.auth.pemfilepath
Warning: Ignoring non-Spark config property: fs.oci.client.auth.userId
20/08/01 06:52:00 WARN Utils: Your hostname resolves to a loopback address: 127.0.0.1; using 192.168.1.41 instead (on interface en0)
20/08/01 06:52:00 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/08/01 06:52:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable方法3: Spark-Submitの使用
Sparkディストリビューションには、spark-submitユーティリティが含まれています。PySparkアプリケーションで追加のJARファイルが必要な場合など、一部の状況でこのメソッドを使用します。
spark-submitを使用してJavaアプリケーションを実行します:spark-submit --class example.Example example.jarメイン・クラス名をデータ・フローに提供する必要があるため、このコードは正しいクラス名を使用していることを確認するのに適しています。クラス名では大文字と小文字が区別されることに注意してください。
spark-submitを使用して、Oracle JDBC JARファイルを必要とするPySparkアプリケーションを実行します:
spark-submit \
--jars java/oraclepki-18.3.jar,java/ojdbc8-18.3.jar,java/osdt_cert-18.3.jar,java/ucp-18.3.jar,java/osdt_core-18.3.jar \
example.py4. アプリケーションのデプロイ
- アプリケーション・アーティファクト(
jarファイル、PythonスクリプトまたはSQLスクリプト)をOracle Cloud Infrastructure Object Storageにコピーします。 - Javaアプリケーションにデータ・フローで提供されていない依存関係がある場合は、アセンブリ
jarファイルを忘れずにコピーしてください。 - Oracle Cloud Infrastructure Object Storage内でこのアーティファクトを参照するデータ・フロー・アプリケーションを作成します。
ステップ3の後、必要に応じてアプリケーションを何度でも実行できます。詳細は、このプロセスのステップを説明しているOracle Cloud Infrastructureデータ・フローの開始チュートリアルを参照してください。
次の手順
これで、アプリケーションをローカルに開発してデータ・フローにデプロイする方法がわかりました。