生成AIエージェントのRAGツール・オブジェクト・ストレージ・ガイドライン
次の項を参照して、生成AIエージェントのRAGツール用のオブジェクト・ストレージ・データを準備します。
一般的なガイドライン
オブジェクト・ストレージにアップロードする前に、生成AIエージェント・データ・ソースのデータを準備するには、次のガイドラインに従います:
- データ・ソース: 生成AIエージェントのデータは、ファイルとしてオブジェクト・ストレージ・バケットにアップロードする必要があります。
- バケット数: データ・ソースごとに許可されるバケットは1つのみです。
- サポートされているファイル・タイプ:
PDF、txt、JSON、HTMLおよびMarkdown (MD)ファイルがサポートされています。 - ファイル・サイズ制限: 各ファイルは100MB以下である必要があります。制限値を超えるファイルは無視されます。その他の要件については、ファイル・タイプの要件およびサポートを参照してください。
- URL: ドキュメントに存在するすべてのハイパーリンクが抽出され、チャット・レスポンスにハイパーリンクとして表示されます。
- データの準備ができていません: データがまだ使用できない場合は、データ・ソースの空のフォルダを作成し、後で移入します。このようにして、フォルダの移入後にデータをソースに取り込むことができます。
続行する前に、次のオブジェクト・ストレージ権限を設定してください。
- オブジェクト・ストレージ・ファイルへのユーザー・アクセス
- 長時間実行ジョブのオブジェクト・ストレージ・ファイルへのデータ取込みジョブ・アクセス
権限については、アクセスの取得を参照してください。
ファイル・タイプの要件とサポート
データ・ソース・ファイルをオブジェクト・ストレージにアップロードする必要があります。取り込むファイルのタイプの要件が満たされていることを確認します。
PDFファイルの収集の要件およびサポートは次のとおりです。
- ファイル拡張子:
.pdfである必要があります - ファイル・サイズ: 1つのファイルが100MBを超えることはできません。
- ファイル・パスワード: PDFファイルがパスワードで保護されている場合、ファイル障害はステータス・ログに記録されます。
- 目次: PDFファイルには、イメージ、チャートおよび参照表を含めることができますが、8MBを超えることはできません。
- チャートの準備: 軸がラベル付けされた2次元であるかぎり、チャートに特別な準備は必要ありません。モデルは、明示的な説明なしでチャートに関する質問に答えることができます。
- 表の準備: 複数の行および列を含む参照表を使用します。たとえば、エージェントは制限ページで表を読み取ることができます。
txt
txtファイルの収集の要件およびサポートは次のとおりです。
- ファイル拡張子:
.txtである必要があります - ファイル・サイズ: 1つのファイルが100MBを超えることはできません。
JSON
JSONファイルの収集の要件およびサポートは次のとおりです。
- ファイル拡張子:
.jsonである必要があります - ファイル・サイズ: 1つのファイルが100MBを超えることはできません。
- エンコーディング: UTF-8エンコーディングのみが英語でサポートされています。JSON構造化データには、キーと値のペア、配列およびネストされたオブジェクトを含めることができます。
- ネスト深度: 構造の深さは50を超えることはできません。
- リスト制限: JSON構造内のリストは、10000アイテムより長くできません。
HTML
HTMLファイルの収集の要件およびサポートは次のとおりです。
- ファイル拡張子:
.htmlである必要があります - ファイル・サイズ: 1つのファイルが100MBを超えることはできません。
- コンテンツ: 表示可能なコンテンツのみが収集されます。動的コンテンツは取り込まれず、スクリプト・タグは削除されます。
- イメージ: ファイルで参照されるイメージは、イメージ・ソースが外部
HTTPまたは絶対パスでない場合に処理できます。次の要件を満たさないイメージは無視されます。JPEGイメージ(.jpgまたは.jpeg)のみがサポートされています。- 1つのイメージは6MBを超えないようにしてください。制限を超えるイメージは無視されます。
- イメージは、アップロードされたHTMLファイルと同じレベルまたはそれ以下でObject Storageにアップロードする必要があります。
- 各イメージのソース・パス(
src属性)は、親HTMLファイルに対する相対パスである必要があります。たとえば:<img src="./my-image.jpg"> <img src="./myfolder/my-imagetwo.jpg"> - 各イメージのソース・パス(
src属性)では、URL (http、httpsまたはdata)を指定しないでください。
MD(値下げ)
MD (Markdown)ファイルの収集の要件とサポートは次のとおりです。
- ファイル拡張子:
.mdである必要があります - ファイル・サイズ: 1つのファイルが100MBを超えることはできません。
- イメージ: イメージは無視され、処理は行われません。
表の強化の理解
RAGツールの機能である強化された表理解は、PDF表データに埋め込まれた回答を使用して問合せに対するレスポンスの精度を向上させることを目的としています。これらのテーブルが処理され、含まれている情報に合わせて、より正確で関連性の高い応答が生成されます。一般に、RAGツールはテーブルを読み取ることができます。RAGツールで、表の理解を深めて表を読み取るには、表に次の機能があることを確認します。
- 表のすべてのセルは、最初の行のヘッダー名を含め、他のセルから表示可能な行またはオブジェクトの境界で区切られます。
- 最初の列を含むすべての列にヘッダー名があります。
- 各表には、複数の列と複数の行があり、ヘッダー名を含む行は除外されます。
Count of tables that support enhanced table understanding in following PDFs:
- enhanced_table_test_data/2025_Report1.pdf has 4 tables processed successfully
- enhanced_table_test_data/2025_Report2.pdf has 3 tables processed successfully
- enhanced_table_test_data/2025_Report3.pdf has 3 tables processed successfully
メタデータ・フィルタリングによるレスポンスの拡張
事前定義されたメタデータを使用して、チャット中にフィルタを適用します。フィルタが適用されると、チャット・セッションでのエージェントの検索は、メタデータに関連付けられているデータファイルに制限され、モデルがコンテンツ・スコープに関連する回答を生成し、エージェントのレスポンスの正確性と関連性を高めるのに役立ちます。
次のステップでは、メタデータ・フィルタリング機能の使用方法の概要を説明します。ワークフローの概要を理解したら、概要ステップの後の項でユースケースの詳細を確認します。
- テキスト・エディタで、メタデータ・スキーマを作成します。このスキーマは、使用可能にするフィルタに必要です。JSON形式でスキーマを記述します。ファイルに
_metadata_schema.jsonという名前を付けます。例:
{ "metadataSchema": [ { "name": "publication_year", "type": "integer" }, { "name": "title", "type": "string" } ] } - ステップ1で作成した
_metadata_schema.jsonファイルを、ナレッジ・ベースのデータファイルを含むオブジェクト・ストレージ・バケットのルート・レベルにアップロードします。 - JSONファイルを作成して、データ・ファイルを事前定義済のメタデータに関連付け、メタデータ値を指定します。
例:
{ "metadataAttributes": { "publication_year": 2020 } }1つ以上のデータファイルまたはバケット内のすべてのファイルをメタデータに関連付けることができます。選択したオプションに使用するJSONファイル名の表記規則の詳細は、メタデータ・フィルタ・オプション(ファイル名および場所)を参照してください。
- ステップ3で作成したJSONファイルを、ナレッジ・ベースのデータファイルを含むオブジェクト・ストレージ・バケットにアップロードします。各オプションについて、ファイルを階層の正しい場所に保存してください。
- ナレッジ・ベースを作成します。データ・ストア・タイプとして「オブジェクト・ストレージ」を選択し、取込みジョブを自動的に開始するオプションを選択します。
データファイルが収集されると、生成AIエージェントは、チャットで選択できるメタデータ名と値のリストを作成します。収集したメタデータ名および値を表示するには、生成AIエージェントでのナレッジ・ベースの詳細の取得を参照してください。
- ステップ5で作成したナレッジ・ベースを選択して、RAGツールを使用してエージェントを作成します。エージェントで、エンドポイントを自動的に作成するオプションを選択します。ヘルプが必要な場合は、エージェントの作成およびRAGツールの作成を参照してください。
- チャット・ウィンドウで、1つ以上の事前定義済メタデータ・フィルタを追加し、適用する値を選択します。チャットでのメタデータ・フィルタの使用を参照してください。
ユースケース用のメタデータJSONファイルの準備、およびチャット・セッションでのメタデータ・フィルタの追加および適用方法についてさらに学習するには、次の項を参照してください。
最適な次の方法を1つ以上選択します。
| Method | ファイル名と保存先 | 使用方法 |
|---|---|---|
| ファイル名を指定せずに、バケット内のすべてのファイルのメタデータを含めます。 | オブジェクト・ストレージのルート・レベルで_common.metadata.jsonファイルを作成します。 |
このファイルは、バケット内のすべてのファイルに共通するメタデータに使用します。この方法は、オブジェクト間でのメタデータの重複入力を回避するのに役立ちます。 |
| 1つのファイルで、バケット内の各ファイルのメタデータ・エントリを作成し、ファイル名を含めます。 | オブジェクト・ストレージのルート・レベルで_all.metadata.jsonファイルを作成します。 |
多数のファイルがあり、すべてのファイル名を含む1つのファイルを作成すると、ファイルごとに1つのメタデータ・ファイルを作成するよりも便利です。 |
| バケット内の各ファイルのメタデータ・ファイルを作成します。 | ファイル・レベルで、ファイルごとに<file-name>.metadata.jsonファイルを作成します。
|
この方法は、メタデータがファイルごとに異なり、メタデータ・ファイルを作成するファイルが多くない場合、またはメタデータ・ファイルの作成を自動化する場合に使用します。 |
| オブジェクト・ストレージ・メタデータ・ヘッダーを各ファイルに追加します。 | 各ファイルのオブジェクト・ストレージ・メタデータ・プロパティを介してメタデータ・ヘッダーを追加します。 | 含めるメタデータ・プロパティがほとんどない場合は、この方法を使用します。ファイルの更新と管理が簡単で、メタデータ・ヘッダーの更新が困難なため、JSONファイルでは他の方法を使用することをお薦めします。 |
すべてのメソッドで、_metadata_schema.jsonというメタデータ・スキーマ・ファイルをオブジェクト・ストレージ・バケットのルート・レベルで定義する必要があります。
必要なメタデータ・ファイルを保存する階層の例を次に示します。
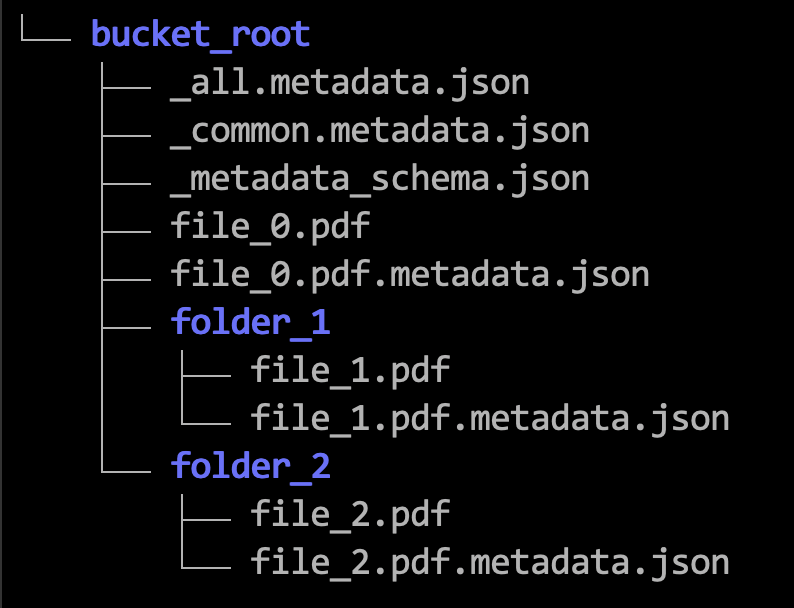
次のステップでは、例を使用して、メタデータJSONファイルのフォーマット方法を示します。メタデータ・フィルタリングの制限も参照してください。
ナレッジ・ベース・データの収集後にメタデータ・フィールドを変更または削除することはできません。許可された制限に新規フィールドを追加できます。フィールドを削除または更新するには、ナレッジ・ベースを再作成します。
次の手順では、必要なメタデータ・スキーマとオプションのメタデータ・フィルタJSONファイル、ナレッジ・ベース、およびRAGツールとエンドポイントを含むエージェントを作成していることを前提としています。
| 内容 | 制限 |
|---|---|
_all.metadata.json内のエントリの最大数 |
10,000 |
| ファイルごとに指定できるメタデータ・フィールドの最大数 | 20 |
list_of_string type内のアイテムの最大数 |
10 |
list_of_string型の個々のアイテムの最大長 |
50 |
| メタデータ・キーの最大長(文字数) | 25 |
| メタデータ値の最大長(文字) | 50 |
オブジェクト・ストレージ・メタデータ・ヘッダーへのメタデータの追加
カスタムURLを使用したオブジェクト・ストレージ・バケットへのデータの追加
ベータ版の顧客:
ベータ・フェーズでナレッジ・ベースを作成した場合は、URL処理機能が動作するように、データ・ソースを削除して再作成する必要がある場合があります。
召喚へのカスタムURLの割当て
metadataオブジェクトにカスタムURLを追加します。このトピックでは、OCI CLIを使用してmetadataオブジェクトを追加または更新する方法について説明します。
- デフォルトの引用をオーバーライドする
metadataオブジェクトには、customized_url_sourceという名前が必要です。 customized_url_sourceという名前のmetadataオブジェクトを1つ持つことができます。- 各
customized_url_sourceにはURLを1つのみ含めることができます。 - ステップ5のコマンドは、現在の
metadataオブジェクトの値を置き換えるため、metadataオブジェクトの追加と更新の両方に有効です。 --metadataオブジェクトの値を、ステップ5のコマンドに示されている形式で渡してください。